Собственно, subj... как это близко и знакомо... ;)
20 августа 2010 г.
19 августа 2010 г.
Архитектура Clariion
Когда-то написал небольшую заметку по архитектуре дисковых массивов Clariion. Может кому пригодится...
На рынке дисковых массивов среднего уровня (mid-range) компания EMC предлагает модельный ряд Clariion, который с 2002 г. активно развивается в рамках серии CX. Последним поколением этих дисковых хранилищ является CX4 UltraFlex (кодовое название Fleet). На рынке SMB предлагаются “облегченное” решение AX4. Архитектурно (но не конструктивно) эти массивы похожи на CX4 и поэтому подробно здесь рассматриваться не будут.

Clariion CX4, как и модели предыдущих серий, является модульной системой. Используются три типа модулей-полок (enclosures):

В дисковых массивах AX4 дисковая полка DAE0 совмещена с Storage Processors в единый модуль DPE (Disk Processor Enclosure).
В рамках технологии UltraFlex, для подключения к серверам (Front-end) и полкам DAE (Back-end) используются специальные интерфейсные модули (I/O modules). Их установка в SPE позволяет достаточно гибко подходить к требуемой конфигурации интерфейсов, снабжая Clariion необходимым количеством портов FC 8Gbps, iSCSI на базе 1Gbit/s или 10Gbit/s Ethernet, а также 10Gbit/s FCoE.

Интерфейс CMI (Clariion Messaging Interface) на базе PCI-express применяется для передачи команд, информации о статусе выполнения запросов между SPs, а также репликации данных кэша на запись.
Карты LCC (Link Control Card) используются для подключения полок DAE, а также функций их контроля (статус датчиков температуры, состояние дисков, включение световых индикаторов и т. д.). В зависимости от модели дискового массива, полки можно подключать посредством 2, 4, 8 или 16 Back-end петель FC_AL. Важно отметить, что в современных дисковых массивах физические петли FC_AL не используются. Вместо этого каждый порт диска подключается к LCC в режиме p-2-p (point-to-point). Процесс инициализации, FC-примитивы и обязательные элементы FC_AL эмулируются специальными контроллерами. Этот подход упрощает подключение к общей петле дисков с различными интерфейсами (FC, SATA, SAS), уменьшает латентность FC_AL, а также более эффективно изолирует ошибки.
Все операции, производимые дисковыми массивами Clariion, контролируются операционной средой FLARE. В моделях CX4 она базируется на 64-битной операционной системе Windows. Функциональность глубоко интегрирована в ОС и реализована при помощи нескольких уровней драйверов. Драйвер Access Logix обеспечивает контроль доступа серверов к логическим томам (LUN masking). Драйверы layered apps обеспечивают работу локальной и удаленной репликации SnapView, MirrorView, RecoverPoint и SAN Copy. Драйверы Flare, прежде всего, отвечают за управление логическими томами LUNs. Их объединение в MetaLUN также контролируется специальным драйвером.

Основные характеристики дисковых массивов Clariion CX4 приведены в таблице.
На рынке дисковых массивов среднего уровня (mid-range) компания EMC предлагает модельный ряд Clariion, который с 2002 г. активно развивается в рамках серии CX. Последним поколением этих дисковых хранилищ является CX4 UltraFlex (кодовое название Fleet). На рынке SMB предлагаются “облегченное” решение AX4. Архитектурно (но не конструктивно) эти массивы похожи на CX4 и поэтому подробно здесь рассматриваться не будут.

Clariion CX4, как и модели предыдущих серий, является модульной системой. Используются три типа модулей-полок (enclosures):
- SPE (Storage Processor Enclosure) содержит один или два интеллектуальных контроллера SP (Storage Processors), которые обеспечивают управление массивом, подключение к серверам и кэширование данных
- DAE (Disk Array Enclosures) имеет 15 слотов для накопителей. Диски внутри полки подключаются к двум независимым петлям FC_AL (Fibre Channel Arbitrated Loop). Дисковый массив в зависимости от модели может состоять из нескольких таких полок.
- SPS (Standby Power Supply) используются для обеспечения питания SPE и первой полки DAE на время сброса данных, находящихся в write cache, в случае проблем с электропитанием.

В дисковых массивах AX4 дисковая полка DAE0 совмещена с Storage Processors в единый модуль DPE (Disk Processor Enclosure).
В рамках технологии UltraFlex, для подключения к серверам (Front-end) и полкам DAE (Back-end) используются специальные интерфейсные модули (I/O modules). Их установка в SPE позволяет достаточно гибко подходить к требуемой конфигурации интерфейсов, снабжая Clariion необходимым количеством портов FC 8Gbps, iSCSI на базе 1Gbit/s или 10Gbit/s Ethernet, а также 10Gbit/s FCoE.

Интерфейс CMI (Clariion Messaging Interface) на базе PCI-express применяется для передачи команд, информации о статусе выполнения запросов между SPs, а также репликации данных кэша на запись.
Карты LCC (Link Control Card) используются для подключения полок DAE, а также функций их контроля (статус датчиков температуры, состояние дисков, включение световых индикаторов и т. д.). В зависимости от модели дискового массива, полки можно подключать посредством 2, 4, 8 или 16 Back-end петель FC_AL. Важно отметить, что в современных дисковых массивах физические петли FC_AL не используются. Вместо этого каждый порт диска подключается к LCC в режиме p-2-p (point-to-point). Процесс инициализации, FC-примитивы и обязательные элементы FC_AL эмулируются специальными контроллерами. Этот подход упрощает подключение к общей петле дисков с различными интерфейсами (FC, SATA, SAS), уменьшает латентность FC_AL, а также более эффективно изолирует ошибки.
Все операции, производимые дисковыми массивами Clariion, контролируются операционной средой FLARE. В моделях CX4 она базируется на 64-битной операционной системе Windows. Функциональность глубоко интегрирована в ОС и реализована при помощи нескольких уровней драйверов. Драйвер Access Logix обеспечивает контроль доступа серверов к логическим томам (LUN masking). Драйверы layered apps обеспечивают работу локальной и удаленной репликации SnapView, MirrorView, RecoverPoint и SAN Copy. Драйверы Flare, прежде всего, отвечают за управление логическими томами LUNs. Их объединение в MetaLUN также контролируется специальным драйвером.
Основные характеристики дисковых массивов Clariion CX4 приведены в таблице.
Характеристика | CX4-120 | CX4-240 | CX4-480 | CX4-960 |
CPU | 2x dual core 1,2Ghz LV-Woodcrest | 2x dual core 1,6Ghz LV-Woodcrest | 2x dual core 2,2Ghz LV-Woodcrest | 2x quad core 2,33Ghz Clovertown |
Системная память | 6 GB | 8 GB | 16 GB | 32 GB |
Максимум write cache | 598 MB | 1261 MB | 4,5 GB | 10,8 GB |
Количество I/O модулей | 6 | 8 | 10 | 12 |
Максимум 4Gbps FE FC портов | 12 | 12 | 16 | 24 |
Базовая конфигурация 4Gbps FE FC портов | 4 | 4 | 8 | 8 |
Максимум 8Gbps FE FC портов | xxx | 12 | 16 | 24 |
Максимум 1Gbit/s iSCSI портов | 8 | 12 | 12 | 16 |
Базовая конфигурация 1Gbit/s iSCSI портов | 4 | 4 | 4 | 4 |
Максимум 10Gbit/s iSCSI портов | 2 | 2 | 4 | 4 |
Максимум 10Gbit/s + 1Gbit/s iSCSI портов | 4 | 8 | 8 | 8 |
Максимум BE 4Gbps FC портов | 2 | 4 | 8 | 16 |
Базовая конфигурация BE 4Gbps FC портов | 2 | 4 | 8 | 8 |
Максимум дисков | 120 | 240 | 480 | 950 |
Максимум Throughput с дисков | 27370 IOPS | 54970 IOPS | 68417 IOPS | 95480 IOPS |
Максимум Bandwidth с дисков | 733 MB/s | 1160 MB/s | 1244 MB/s | 3020 MB/s |
10 августа 2010 г.
Windows в Clariion
Где-то с год назад я натолкнулся на очень интересный пост о набившей уже многим оскомину теме Windows в Clariion. Он был напечатан в блоге одного из девелоперов FLARE старой гвардии, известного популяризатора инновационного подхода к разработке продуктов Стива Тода. И вот я все-таки сподобился его перевести. Оригинал здесь.
"Решение о Windows
Одним из наиболее интересных моментов в дискуссиях по поводу CLARiiON является факт того, что внутри него “крутится” Windows XP embedded. Некоторые читатели спрашивали меня об этом. Также я обнаружил множество запросов в Google с попыткой найти на моем сайте побольше информации на эту тему. Многие любопытствуют, почему и когда было принято решение об использовании Windows? Ведь в 90-е годы CLARiiON не был продуктом на Windows.
Хорошо, у меня есть ответы. Предупреждаю, что они могут несколько отличаться от других ответов на эту тему, которые вы уже, возможно, получали. Мои воспоминания являются точкой зрения программного архитектора.
Как я помню, была необходимость в смене архитектуры CLARiiON по одной основной причине: конкуренция против EMC.
В конце 90-х CLARiiON был продуктом, разработанным компанией Data General. Я участвовал в создании программной архитектуры микрокода CLARiiON, известной как FLARE. Начиная с 80-х я отвечал за алгоритмы RAID, кэш на запись и обработки ошибок (горячее восстановление, переключение и обратное переключение в случае сбоев компонент), а также за все связанное с целостностью данных.
Архитектура, основанная на процессах
Первоначально программная архитектура FLARE была просто набором процессов. Для каждого диска был свой процесс. Был процесс для обработки запросов на чтение и запись от приложений на серверах. Был процесс перестроения RAID, фоновый процесс верификации, процесс для выполнения настроек и т. д. Операционная среда для всех этих процессов была самодельной проприетарной системой, которая называлась HEMI (потому, что планировщик в ней использовал полусферический (hemispherical) алгоритм).
В первые 6 или 7 лет существования мы добавляли в нее новую функциональность. Мы добавили поддержку протокола SCSI. Мы добавили поддержку дисков горячей замены. Мы добавили кэш на запись, поддержку новых уровней RAID, улучшенную производительность и добавили поддержку графического пользовательского интерфейса. Мы ушли от фиксированного количества дисков при помощи возможности добавления новых полок. Мы добавили поддержку SAN (например, LUN маскинг). Первоначальная архитектура вобрала в себя все это и доказала свою масштабируемость и сервисо-пригодность.
И по мере того, как в середине и конце 90-х рынок хранения данных просто взлетел, парни, заведующие бизнесом CLARiiON, все чаще стали посматривать на огромные прибыли, которые могли принести системы хранения верхнего уровня, такие как EMC Symmetrix. Эти продукты уже мешали друг другу в случае продаж, когда заказчик рассматривал возможность приобретения “нажнего хай-энда” либо “верхнего мидренджа”.
Symm против CLARiiON
Определенно, Symmetrix был сильным игроком и одна из основных сложностей конкуренции с ним была в том, что Symm имел возможность соединения с огромным количеством серверов (обеспечивая это большим объемом кэш). Но DG в основном думала не о аппаратном обеспечении, а о допольнительных программных возможностях, которые генерировали громадные доходы: SRDF и TimeFinder. CLARiiON не имел такой функциональности. Для все большего количества заказчиков удаленная репликация и возможность создания мгновенных снимков стали основополагающим фактором, а CLARiiON ими не обладал.
К счастью, CLARiiON имел несколько других выдающихся достоинств. Symm (в то время) не имел алгоритмов работы с RAID-5, зеркалируемого кэш на запись и не обладал простым графическим пользовательским интерфейсом (Navisphere). Но без удаленной репликации и возможностей создания мгновенных снимков CLARiiON не мог конкурировать. Удаленная репликация и мгновенные снимки указывали на то, что программная архитектура CLARiiON, основанная на процессах имеет некоторые недостатки.
Уровни против процессов
Как я уже упоминал, FLARE имел front-end процесс для обработки входящих запросов от приложений на серверах. Этот процесс также поддерживал кэш на запись. Когда данные из кэш перемещались на диск, front-end процесс должен был "открыть коннект" с соответствующим другим процессом и послать ему "сообщение". А так как количество дисков сначала возросло с 20 до 30, потом до 40 и, в конце концов, до 120, во FLARE добавлялось все большее и большее число процессов. Коннекты между всеми этими процессами реализовывались огромным количеством пайпов, через которые пересылалось чудовищное количество сообщений.
Решение о том, куда все-таки вставить функциональность удаленной репликации и мгновенных снимков, не было очевидным. Добавление нового процесса привело бы к еще большим “пляскам с балалайкой”. Модификация существующих процессов размыло бы четкие границы архитектуры и нарушила бы инкапсуляцию функций. Существовали опасения насчет производительности и поддержки архитектуры.
Было бы здорово, если бы FLARE поддерживала “включение” этой функциональности более реализуемым способом не тревожа функциональность таких компонент как кэш на запись и алгоритмы RAID. Ну, типа как в многоуровневой реализации поддержки устройств. Эй, а разве Windows не использует отличную многоуровневую модель стека устройств?
Реакция на решение
Вы можете себе представить, с каким скептицизмом внутри компании было встречено известие о переводе FLARE на Windows embedded. На вопросы о том, будет ли FLARE показывать заказчикам “синие экраны” в шутку отвечали: “мы просто не собираемся для этого поставлять экраны” ;>). Мягко говоря, это было несколько спорное внутренне решение.
Заказчики также отнеслись к нему скептически. Один из наших вице-президентов встречался со многими клиентами, которые регулярно задавали ему вопросы об уровне качества нового продукта. К его чести, он признавал, что переход на новую архитектуру в самом начале может вызвать некоторые проблемы с качеством. Однако, DG и не имело причин скрывать проблемы с качеством, т. к. в заднем кармане у нее был такой козырь, как DAQ. ПО Disk Array Qualifier все еще гоняет свой комплект тестов целостности данных и проверяет на прочность новые решения на базе Windows. DAQ запускался как на старой, так и на новой архитектуре благодаря так называемым “крючкам качества” которые всегда были частью FLARE и которые работали на Windows. Кэш на чтение мог быть полностью протестирован.
Это удовлетворяло опасения заказчиков. И когда они поняли, что многоуровневый стек устройств обеспечивает, во первых, лучшую производительность и, во вторых, возможность внедрения функциональности в конкретный уровень не затрагивая другой существующий код, они начали инвестировать в новую архитектуру.
Это работает
Разработчики программного обеспечения для CLARiiON проделали отличную работу перегруппируя различные части процессов архитектуры HEMI в разные уровни стека драйверов Windows. Производительность была превосходной (особенно после того, как кэш на запись был портирован без проблем). Новые драйвера устройств удаленной репликации и мгновенных снимков реализованы в виде уровней поверх базовой функциональности HEMI.
Смелое решение оправдало себя. DG было приобретено EMC. На сколько хорошо EMC продало решение, основанное на Windows? Посмотрите последний пресс-релиз об анонсе массивов CX в начале августа (прим. пост был опубликован 28 августа 2008 г.). EMC докладывает о продаже более, чем 300000 CLARiiON, каждый из которых имеет доступность 99.999. Качество , производительность, гибкость и доход. Откровенно говоря, более 300000 CLARiiON, работающих по всему миру, все еще удивляют меня. Вот что случается, когда стораджевый продукт куплен стораджевой компанией.
Дополнительные многоуровневые драйверы разрабатывались годами и о некоторых из них я надеюсь написать в будущих постах.
Стив"
PS Кстати, в прошлом году я немного пообщался со Стивом в питерском центре разработки EMC. Надо сказать, очень обаятельный и увлеченный своим делом дядька...
"Решение о Windows
Одним из наиболее интересных моментов в дискуссиях по поводу CLARiiON является факт того, что внутри него “крутится” Windows XP embedded. Некоторые читатели спрашивали меня об этом. Также я обнаружил множество запросов в Google с попыткой найти на моем сайте побольше информации на эту тему. Многие любопытствуют, почему и когда было принято решение об использовании Windows? Ведь в 90-е годы CLARiiON не был продуктом на Windows.
Хорошо, у меня есть ответы. Предупреждаю, что они могут несколько отличаться от других ответов на эту тему, которые вы уже, возможно, получали. Мои воспоминания являются точкой зрения программного архитектора.
Как я помню, была необходимость в смене архитектуры CLARiiON по одной основной причине: конкуренция против EMC.
В конце 90-х CLARiiON был продуктом, разработанным компанией Data General. Я участвовал в создании программной архитектуры микрокода CLARiiON, известной как FLARE. Начиная с 80-х я отвечал за алгоритмы RAID, кэш на запись и обработки ошибок (горячее восстановление, переключение и обратное переключение в случае сбоев компонент), а также за все связанное с целостностью данных.
Архитектура, основанная на процессах
Первоначально программная архитектура FLARE была просто набором процессов. Для каждого диска был свой процесс. Был процесс для обработки запросов на чтение и запись от приложений на серверах. Был процесс перестроения RAID, фоновый процесс верификации, процесс для выполнения настроек и т. д. Операционная среда для всех этих процессов была самодельной проприетарной системой, которая называлась HEMI (потому, что планировщик в ней использовал полусферический (hemispherical) алгоритм).
В первые 6 или 7 лет существования мы добавляли в нее новую функциональность. Мы добавили поддержку протокола SCSI. Мы добавили поддержку дисков горячей замены. Мы добавили кэш на запись, поддержку новых уровней RAID, улучшенную производительность и добавили поддержку графического пользовательского интерфейса. Мы ушли от фиксированного количества дисков при помощи возможности добавления новых полок. Мы добавили поддержку SAN (например, LUN маскинг). Первоначальная архитектура вобрала в себя все это и доказала свою масштабируемость и сервисо-пригодность.
И по мере того, как в середине и конце 90-х рынок хранения данных просто взлетел, парни, заведующие бизнесом CLARiiON, все чаще стали посматривать на огромные прибыли, которые могли принести системы хранения верхнего уровня, такие как EMC Symmetrix. Эти продукты уже мешали друг другу в случае продаж, когда заказчик рассматривал возможность приобретения “нажнего хай-энда” либо “верхнего мидренджа”.
Symm против CLARiiON
Определенно, Symmetrix был сильным игроком и одна из основных сложностей конкуренции с ним была в том, что Symm имел возможность соединения с огромным количеством серверов (обеспечивая это большим объемом кэш). Но DG в основном думала не о аппаратном обеспечении, а о допольнительных программных возможностях, которые генерировали громадные доходы: SRDF и TimeFinder. CLARiiON не имел такой функциональности. Для все большего количества заказчиков удаленная репликация и возможность создания мгновенных снимков стали основополагающим фактором, а CLARiiON ими не обладал.
К счастью, CLARiiON имел несколько других выдающихся достоинств. Symm (в то время) не имел алгоритмов работы с RAID-5, зеркалируемого кэш на запись и не обладал простым графическим пользовательским интерфейсом (Navisphere). Но без удаленной репликации и возможностей создания мгновенных снимков CLARiiON не мог конкурировать. Удаленная репликация и мгновенные снимки указывали на то, что программная архитектура CLARiiON, основанная на процессах имеет некоторые недостатки.
Уровни против процессов
Как я уже упоминал, FLARE имел front-end процесс для обработки входящих запросов от приложений на серверах. Этот процесс также поддерживал кэш на запись. Когда данные из кэш перемещались на диск, front-end процесс должен был "открыть коннект" с соответствующим другим процессом и послать ему "сообщение". А так как количество дисков сначала возросло с 20 до 30, потом до 40 и, в конце концов, до 120, во FLARE добавлялось все большее и большее число процессов. Коннекты между всеми этими процессами реализовывались огромным количеством пайпов, через которые пересылалось чудовищное количество сообщений.
Решение о том, куда все-таки вставить функциональность удаленной репликации и мгновенных снимков, не было очевидным. Добавление нового процесса привело бы к еще большим “пляскам с балалайкой”. Модификация существующих процессов размыло бы четкие границы архитектуры и нарушила бы инкапсуляцию функций. Существовали опасения насчет производительности и поддержки архитектуры.
Было бы здорово, если бы FLARE поддерживала “включение” этой функциональности более реализуемым способом не тревожа функциональность таких компонент как кэш на запись и алгоритмы RAID. Ну, типа как в многоуровневой реализации поддержки устройств. Эй, а разве Windows не использует отличную многоуровневую модель стека устройств?
Реакция на решение
Вы можете себе представить, с каким скептицизмом внутри компании было встречено известие о переводе FLARE на Windows embedded. На вопросы о том, будет ли FLARE показывать заказчикам “синие экраны” в шутку отвечали: “мы просто не собираемся для этого поставлять экраны” ;>). Мягко говоря, это было несколько спорное внутренне решение.
Заказчики также отнеслись к нему скептически. Один из наших вице-президентов встречался со многими клиентами, которые регулярно задавали ему вопросы об уровне качества нового продукта. К его чести, он признавал, что переход на новую архитектуру в самом начале может вызвать некоторые проблемы с качеством. Однако, DG и не имело причин скрывать проблемы с качеством, т. к. в заднем кармане у нее был такой козырь, как DAQ. ПО Disk Array Qualifier все еще гоняет свой комплект тестов целостности данных и проверяет на прочность новые решения на базе Windows. DAQ запускался как на старой, так и на новой архитектуре благодаря так называемым “крючкам качества” которые всегда были частью FLARE и которые работали на Windows. Кэш на чтение мог быть полностью протестирован.
Это удовлетворяло опасения заказчиков. И когда они поняли, что многоуровневый стек устройств обеспечивает, во первых, лучшую производительность и, во вторых, возможность внедрения функциональности в конкретный уровень не затрагивая другой существующий код, они начали инвестировать в новую архитектуру.
Это работает
Разработчики программного обеспечения для CLARiiON проделали отличную работу перегруппируя различные части процессов архитектуры HEMI в разные уровни стека драйверов Windows. Производительность была превосходной (особенно после того, как кэш на запись был портирован без проблем). Новые драйвера устройств удаленной репликации и мгновенных снимков реализованы в виде уровней поверх базовой функциональности HEMI.
Смелое решение оправдало себя. DG было приобретено EMC. На сколько хорошо EMC продало решение, основанное на Windows? Посмотрите последний пресс-релиз об анонсе массивов CX в начале августа (прим. пост был опубликован 28 августа 2008 г.). EMC докладывает о продаже более, чем 300000 CLARiiON, каждый из которых имеет доступность 99.999. Качество , производительность, гибкость и доход. Откровенно говоря, более 300000 CLARiiON, работающих по всему миру, все еще удивляют меня. Вот что случается, когда стораджевый продукт куплен стораджевой компанией.
Дополнительные многоуровневые драйверы разрабатывались годами и о некоторых из них я надеюсь написать в будущих постах.
Стив"
PS Кстати, в прошлом году я немного пообщался со Стивом в питерском центре разработки EMC. Надо сказать, очень обаятельный и увлеченный своим делом дядька...
5 августа 2010 г.
20% Guaranteed
Пара забавных рекламных роликов о платформе EMC Unified Storage. Если не получите 20%, требуйте в магазине возврата товара... :)
Про гольф:
Про превышение скорости:
Про гольф:
Про превышение скорости:
4 августа 2010 г.
Rebuild на массивах Clariion
Давайте немного поговорим о перестройке (rebuild) данных на hot spare в слeчае сбоя диска на массивах Clariion.
Начать надо с того, что при ребилде операционная среда Flare работает не со всем диском, а на уровне конкретных LUNs. При этом, единовременно может перестраиваться только один том. Процедура rebuild считается законченной только тогда, когда будут последовательно перестроены все LUNs, находящиеся на диске. За выполнение операции отвечает owner SP. Соответственно, ребилдом различных LUNs на одном диске попеременно будут заниматься оба Storage Processors.
Выбор томов для ребилда производится в соответствии со следующей перевернутой пирамидой:

При ребилде RAID1 или RAID10 кусок данных, состоящий из трех блоков по 512KB просто считываются со “здорового” подзеркала и записываются на Hot Spare.

При перестройке RAID3, RAID5 или RAID6 одновременно считываются данные всего страйпа RAID Groups. Обычно это происходит кусками, состоящими из 8x блоков по 512KB. SP пересчитывает данные и parity, а потом записывает их на Hot Spare.

В случае, когда LUN имеет ASAP rebuild priority, после завершения операции копирования немедленно начинается следующая итерация. Такой подход, конечно, очень сильно влияет на нагрузку дискового массива в целом и может негативно сказаться на производительности доступа к данным со стороны хостов. Если же том имеет приоритет High, Medium или Low, следующая операция начинается только после некоторой заранее определенной задержки. Однако, случае простоя дискового массива (нет операций ввода-вывода с хостов) не зависимо от текущего приоритета будет всегда применяться режим ASAP.
При ребилде не используются области кэш, выделенные для чтения и записи данных. Временное размещение данных происходит в системной области памяти.
Если во время описанного процесса какой-либо хост запишет данные в блоки сбойного диска информация будет либо сразу помещаться на Hot Spare (в случае если эти блоки уже были перестроены или используется RAID10), либо будут временно записана в блок, в котором хранится parity данного stripe (RAID5, RAID6 parity shedding). В момент непосредственного ребилда конкретного stripe, все операции записи или сброса кэш временно приостанавливаются.
При выполнении операций rebuild и pro-active copy внутренняя буферизация диска всегда отключается. Это приводит к некоторому увеличению времени выполнения операций.
В процессе перестроения данных всегда выставляются чекпоинты. Поэтому если при ребилде произойдет выключение дискового массива в связи со сбоем питания, то после следующей загрузки Clariion, перестроение будет продолжено с момента последнего чекпоинта. К сожалению я не знаю точных деталей того, как это работает. Предположительно, чекпоинты записываются в полях rebuild time записей CRU Signature, находящейся в зарезервированной 34MB области каждого диска. Но это только предположение. Если кто-либо из читателей точно знает, как это происходит, хотя бы намекните в комментах к этому посту.
После замены сбойного диска начинается обратный процесс эквалайзинга (equalize). Данные копируются с Hot spare на новый диск. Необходимо помнить, что если вы заменили диск достаточно оперативно и процесс ребилда еще не закончился, то эквалайзинг начнется только после полного окончания перестроения диска на Hot spare т. к. процесс ребилда прервать нельзя.

Значения Bandwidth и дополнительной нагрузки на SP при ребилде и эквалайзинге сильно зависят от семейства Clariion (CX, CX3, CX4) и версии Flare. Поэтому за их точными значениями я отсылаю к соответствующим открытым best practices на powerlink. Однако, можно вкратце отметить несколько факторов, от которых зависит скорость перестроения:
Начать надо с того, что при ребилде операционная среда Flare работает не со всем диском, а на уровне конкретных LUNs. При этом, единовременно может перестраиваться только один том. Процедура rebuild считается законченной только тогда, когда будут последовательно перестроены все LUNs, находящиеся на диске. За выполнение операции отвечает owner SP. Соответственно, ребилдом различных LUNs на одном диске попеременно будут заниматься оба Storage Processors.
Выбор томов для ребилда производится в соответствии со следующей перевернутой пирамидой:

При ребилде RAID1 или RAID10 кусок данных, состоящий из трех блоков по 512KB просто считываются со “здорового” подзеркала и записываются на Hot Spare.

При перестройке RAID3, RAID5 или RAID6 одновременно считываются данные всего страйпа RAID Groups. Обычно это происходит кусками, состоящими из 8x блоков по 512KB. SP пересчитывает данные и parity, а потом записывает их на Hot Spare.

В случае, когда LUN имеет ASAP rebuild priority, после завершения операции копирования немедленно начинается следующая итерация. Такой подход, конечно, очень сильно влияет на нагрузку дискового массива в целом и может негативно сказаться на производительности доступа к данным со стороны хостов. Если же том имеет приоритет High, Medium или Low, следующая операция начинается только после некоторой заранее определенной задержки. Однако, случае простоя дискового массива (нет операций ввода-вывода с хостов) не зависимо от текущего приоритета будет всегда применяться режим ASAP.
При ребилде не используются области кэш, выделенные для чтения и записи данных. Временное размещение данных происходит в системной области памяти.
Если во время описанного процесса какой-либо хост запишет данные в блоки сбойного диска информация будет либо сразу помещаться на Hot Spare (в случае если эти блоки уже были перестроены или используется RAID10), либо будут временно записана в блок, в котором хранится parity данного stripe (RAID5, RAID6 parity shedding). В момент непосредственного ребилда конкретного stripe, все операции записи или сброса кэш временно приостанавливаются.
При выполнении операций rebuild и pro-active copy внутренняя буферизация диска всегда отключается. Это приводит к некоторому увеличению времени выполнения операций.
В процессе перестроения данных всегда выставляются чекпоинты. Поэтому если при ребилде произойдет выключение дискового массива в связи со сбоем питания, то после следующей загрузки Clariion, перестроение будет продолжено с момента последнего чекпоинта. К сожалению я не знаю точных деталей того, как это работает. Предположительно, чекпоинты записываются в полях rebuild time записей CRU Signature, находящейся в зарезервированной 34MB области каждого диска. Но это только предположение. Если кто-либо из читателей точно знает, как это происходит, хотя бы намекните в комментах к этому посту.
После замены сбойного диска начинается обратный процесс эквалайзинга (equalize). Данные копируются с Hot spare на новый диск. Необходимо помнить, что если вы заменили диск достаточно оперативно и процесс ребилда еще не закончился, то эквалайзинг начнется только после полного окончания перестроения диска на Hot spare т. к. процесс ребилда прервать нельзя.

Значения Bandwidth и дополнительной нагрузки на SP при ребилде и эквалайзинге сильно зависят от семейства Clariion (CX, CX3, CX4) и версии Flare. Поэтому за их точными значениями я отсылаю к соответствующим открытым best practices на powerlink. Однако, можно вкратце отметить несколько факторов, от которых зависит скорость перестроения:
- Конечно, rebuild bandwidth растет с повышение приоритета.
- За счет отсутствия необходимости пересчета parity при равном количестве дисков, ребилд RAID10 происходит значительно быстрее, чем RAID5 или RAID6.
- При повышении количества дисков в RAID5 и RAID6 скорость перестроения данных заметно падает.
- Если принять скорость ребилда дисков FC 4Gbps 15K RPM за 1, то для дисков FC 2Gbps 10K RPM она будет равна 0,65, для SATA 7.5K RPM – 0,75, а для EFD (SSD) – 1,43.
- За счет высоких требований к пересчету parity, дополнительная нагрузка на процессоры SP при ребилде RAID5 и RAID6, состоящими из многих дисков, достаточно велика (до 20%).
24 мая 2010 г.
Кто оплачивает "воздух"?
Оригинальный пост здесь
В нашей современной культуре чисто промытых мозгов, одним из основных двигателей прогресса является красивая многослойная упаковка. Мы много работаем и значительная часть наших усилий идет на приобретение миллионов тонн ненужного пластика и картона. Каждый участвует в процессе массовой вырубки лесов и превращения полезных ископаемых в горы бесполезного мусора. И, обратите внимание, делает это с удовольствием.
Проблема очевидна и не использовать ее в качестве еще одной маркетинговой заманухи было бы глупо. Только ленивый в наше время не говорит об экологичности технологий, с гордостью не сообщает о "зеленом" производстве и салатовых энергопотреблении и тепловыделении. Постараюсь быть справедливым, и отмечу, что некий прогресс в этом направлении есть. Правда, он является не основной целью, а, как бы это выразиться, побочным эффектом. Согласитесь, что те же упомянутые выше тепловыделение и энергопотребление оптимизируются в первую очередь не из за экологии, а в связи с более приземленными техническими проблемами.
Однако, если в технологиях наблюдается хоть какое-нибудь движение в правильную сторону, то в таких "пустяковых" вещах как упаковка и логистика производители оборудования зачастую еще находятся на стадии неандертальцев. Правда иногда об экологических моментах вспоминать и вовсе не приходится . Вопросы уже вызывают наличие здравого смысла и элементарной экономической целесообразности.
Вот один из прецедентов. Заказчику приходит коробка.

Ее открывают и обнаруживают ворох пластикового "воздуха"...

.. в котором откапывают упаковку поменьше...

..и в ней находятся 2 жестких диска.

Теперь вопрос знатокам: каковы дополнительные затраты на материалы, упаковку, перевозку и утилизацию доставленного по назначению "воздуха"?
А еще кто все в итоге оплачивает? ... Правильно, Заказчик...

PS Поговаривают, что иногда в таких коробках посылают даже лицензии... ;(
В нашей современной культуре чисто промытых мозгов, одним из основных двигателей прогресса является красивая многослойная упаковка. Мы много работаем и значительная часть наших усилий идет на приобретение миллионов тонн ненужного пластика и картона. Каждый участвует в процессе массовой вырубки лесов и превращения полезных ископаемых в горы бесполезного мусора. И, обратите внимание, делает это с удовольствием.
Проблема очевидна и не использовать ее в качестве еще одной маркетинговой заманухи было бы глупо. Только ленивый в наше время не говорит об экологичности технологий, с гордостью не сообщает о "зеленом" производстве и салатовых энергопотреблении и тепловыделении. Постараюсь быть справедливым, и отмечу, что некий прогресс в этом направлении есть. Правда, он является не основной целью, а, как бы это выразиться, побочным эффектом. Согласитесь, что те же упомянутые выше тепловыделение и энергопотребление оптимизируются в первую очередь не из за экологии, а в связи с более приземленными техническими проблемами.
Однако, если в технологиях наблюдается хоть какое-нибудь движение в правильную сторону, то в таких "пустяковых" вещах как упаковка и логистика производители оборудования зачастую еще находятся на стадии неандертальцев. Правда иногда об экологических моментах вспоминать и вовсе не приходится . Вопросы уже вызывают наличие здравого смысла и элементарной экономической целесообразности.
Вот один из прецедентов. Заказчику приходит коробка.
Ее открывают и обнаруживают ворох пластикового "воздуха"...
.. в котором откапывают упаковку поменьше...
..и в ней находятся 2 жестких диска.
Теперь вопрос знатокам: каковы дополнительные затраты на материалы, упаковку, перевозку и утилизацию доставленного по назначению "воздуха"?
А еще кто все в итоге оплачивает? ... Правильно, Заказчик...
PS Поговаривают, что иногда в таких коробках посылают даже лицензии... ;(
17 мая 2010 г.
Disk crossing и Partition Alignment
Проблема, описанная в данном посте, является общей для достаточно большого количества дисковых массивов различных производителей и моделей. Однако, для большей наглядности я поговорю о ней на примере конкретного хранилища EMC Clariion. Итак, как я уже писал в посте об организации RAID в массивах Clariion, по умолчанию размер Stripe element равен 64KB.

При выполнении операции ввода-вывода, оптимальным вариантом будет чтение или запись, зависящая от минимально возможного количества шпинделей. Очевидно, что для операций блоками <=64KB это будут обращения только к одному физическому диску.

Однако, бывают ситуации, когда адресация блока даже небольшого размера по каким-то причинам смещена, что, в свою очередь, приводит к тому, что количество физических накопителей, к которым будет необходимо обратиться, увеличится на 1.

При блоках <=64KB это приводит к удвоению количества требуемых операций. Особенно это критично при записи данных в RAID 5, когда и без того высокое значение Write Penalty=4 увеличится до 8.

Ситуация, когда одна операция ввода-вывода требует обращения к данным (Parity не считается) на нескольких физических накопителях называется пересечение границы диска (Disk Crossing). При анализе статистических данных о производительности дисковых массивов Clariion, необходимо учитывать, что метрика Disk Crossing инкрементируется на 1 при выполнении всей операции, не зависимо от количества “пересекаемых” шпинделей.
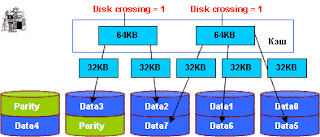
Пересечение границ страйпа Stripe Crossing также может негативно влиять на производительность. Так, высокоэффективный Full Stripe Write может “превратиться” в медленную запись нескольких независимых блоков.

Чаще всего причиной Disk Crossing является отсутствие выравнивания разделов в серверах архитектуры x86. Давайте рассмотрим это более подробно. Дело в том, что первый сектор диска (LBA 0) всегда содержит обязательную запись MBR (Master Boot Record), которая хранит таблицу разделов диска (partition table) и крохотную область кода, при необходимости используемую для передачи управления загрузчику ОС (boot loader) с активного раздела.
Новые разделы (partitions) на жестком диске по умолчанию создаются по границам треков. Но т. к. в первом треке уже записаны данные MBR, то раздел 0 приходится создавать с начала следующего трека, пропустив 63 блока LBA (32256 Bytes) Это мы уже видели здесь. Получается, что данные, записанные в раздел всегда будут смещены на 32256 Bytes относительно начала страйпа, что приводит к сдвигу адресации.
Естественно, такое смещение не всегда будет приводить к появлению Disk Crossing. Его вероятность зависит от размера операций, которыми записываются данные. Так, при записи 4KB, вероятность Disk Crossing будет равна 5,5% (4KB это 8 блоков по 512KB, (7/128)*100=5.5%. А при записи 16KB уже 24%. Конечно, запись данных размером >64KB будет приводить к инкрементации метрики Disk Crossing при любых обстоятельствах.

Для оптимизации производительности необходимо выровнять раздел (Partition Alignment) по границам 64KB Stripe Element. Для этого необходимо использовать утилиты, описанные в таблице.
В идеале, неплохо было бы избежать Stripe Crossing и выравнивать раздел не на 64KB, а сразу на размер всего страйпа.
Добавлено
При создании разделов в Windows 2008, Vista и Windows 7 разделы создаются по границе 1MB и в выравнивании не нуждаются.
Тома VMware VMFS-3 при создании через vClient также автоматически выравниваются по границе 64KB. И их тоже выравнивать не надо. Однако, это не относится к томам на уровне самих виртуальных машин. Каждую ВМ придется выравнивать внутри .vmdk файлов
Случаи создания томов средствами LVM без использования стандартных разделов ОС необходимо рассмотривать индивидуально. Так, при использовании Physical Volumes в LVM ОС Linux выравнивание не нужно. Это связано с тем, что размер метаданных PV сам по себе кратен 64KB.
О Morley Parity здесь...

При выполнении операции ввода-вывода, оптимальным вариантом будет чтение или запись, зависящая от минимально возможного количества шпинделей. Очевидно, что для операций блоками <=64KB это будут обращения только к одному физическому диску.

Однако, бывают ситуации, когда адресация блока даже небольшого размера по каким-то причинам смещена, что, в свою очередь, приводит к тому, что количество физических накопителей, к которым будет необходимо обратиться, увеличится на 1.

При блоках <=64KB это приводит к удвоению количества требуемых операций. Особенно это критично при записи данных в RAID 5, когда и без того высокое значение Write Penalty=4 увеличится до 8.

Ситуация, когда одна операция ввода-вывода требует обращения к данным (Parity не считается) на нескольких физических накопителях называется пересечение границы диска (Disk Crossing). При анализе статистических данных о производительности дисковых массивов Clariion, необходимо учитывать, что метрика Disk Crossing инкрементируется на 1 при выполнении всей операции, не зависимо от количества “пересекаемых” шпинделей.

Пересечение границ страйпа Stripe Crossing также может негативно влиять на производительность. Так, высокоэффективный Full Stripe Write может “превратиться” в медленную запись нескольких независимых блоков.

Чаще всего причиной Disk Crossing является отсутствие выравнивания разделов в серверах архитектуры x86. Давайте рассмотрим это более подробно. Дело в том, что первый сектор диска (LBA 0) всегда содержит обязательную запись MBR (Master Boot Record), которая хранит таблицу разделов диска (partition table) и крохотную область кода, при необходимости используемую для передачи управления загрузчику ОС (boot loader) с активного раздела.
Новые разделы (partitions) на жестком диске по умолчанию создаются по границам треков. Но т. к. в первом треке уже записаны данные MBR, то раздел 0 приходится создавать с начала следующего трека, пропустив 63 блока LBA (32256 Bytes) Это мы уже видели здесь. Получается, что данные, записанные в раздел всегда будут смещены на 32256 Bytes относительно начала страйпа, что приводит к сдвигу адресации.
Естественно, такое смещение не всегда будет приводить к появлению Disk Crossing. Его вероятность зависит от размера операций, которыми записываются данные. Так, при записи 4KB, вероятность Disk Crossing будет равна 5,5% (4KB это 8 блоков по 512KB, (7/128)*100=5.5%. А при записи 16KB уже 24%. Конечно, запись данных размером >64KB будет приводить к инкрементации метрики Disk Crossing при любых обстоятельствах.

Для оптимизации производительности необходимо выровнять раздел (Partition Alignment) по границам 64KB Stripe Element. Для этого необходимо использовать утилиты, описанные в таблице.
Утилита | ОС | Параметры | Комментарии |
diskpar | Windows NT и выше | Starting Offset in sectors = 128 | не входит в дистрибутив ОС, можно установить из Microsoft Windows 2000 Resource Kit |
diskpart | Windows 2003 SP1 и выше | Primary Align = 64 | входит в дистрибутив ОС с Windows 2000, но начала поддерживать partition alignment только с версии 5.2.3790, которая появилась в Win 2003 SP1 |
fdisk | Linux | adjust starting block number = 128 | в expert mode |
VMware ESX | adjust starting block for partition = 128 | в expert mode |
В идеале, неплохо было бы избежать Stripe Crossing и выравнивать раздел не на 64KB, а сразу на размер всего страйпа.
Добавлено
При создании разделов в Windows 2008, Vista и Windows 7 разделы создаются по границе 1MB и в выравнивании не нуждаются.
Тома VMware VMFS-3 при создании через vClient также автоматически выравниваются по границе 64KB. И их тоже выравнивать не надо. Однако, это не относится к томам на уровне самих виртуальных машин. Каждую ВМ придется выравнивать внутри .vmdk файлов
Случаи создания томов средствами LVM без использования стандартных разделов ОС необходимо рассмотривать индивидуально. Так, при использовании Physical Volumes в LVM ОС Linux выравнивание не нужно. Это связано с тем, что размер метаданных PV сам по себе кратен 64KB.
О Morley Parity здесь...
13 мая 2010 г.
Flash-память (часть 2 SSD)
Как я уже писал раньше, flash-накопители (SSD или EFD), которые используются в дисковых массивах, выпускаются на базе архитектуры NAND. Ключевыми элементами накопителей являются сами чипы flash-памяти NAND, память SDRAM, которая выполняет функции кэша данных и хранилища таблиц трансляции логических адресов, а также чипы ввода-вывода, обеспечивающих одновременный доступ к данным по нескольким параллельным каналам.

Ячейки сгруппированы в страницы (pages) по 4KB (в накопителях первого поколения 73GB и 146GB) или 16KB (в накопителях 200GB и 400GB). Именно страница является атомарной единицей при обращении к SSD диску. Поэтому при записи порции данных размером меньше страницы, обязательна процедура read-modify-write при которой целая страница предварительно считывается с накопителя, в нее вносятся изменения и далее она снова записывается на SSD. Конечно, это сказывается на производительности записи.
Страницы, в свою очередь, сгруппированы в блоки (blocks) размером 256KB.

Для адресации страницы используется специальная таблица LBA->NAND. В ней каждому логическому адресу LBA ставится в соответствие физическая координата текущего местоположения данных, т. е. номера блока и страницы в нем. На рисунке ниже приведен пример адресации ячейки и записи данных. После выборки адреса блока и страницы, данные могут быть физически записаны в энергонезависимую память.

Биты готовой к записи ячейки всегда хранят значение 1 (низкий заряд). Переключение 1 в 0 является штатной операцией над индивидуальными ячейками. А вот переключение из 0 в 1 в flash NAND возможно только стиранием блока целиком. После этой операции все ячейки опять переводятся в состояние 1, а все страницы блока получают статус Erased. Первая запись данных в страницу изменяет ее статус на Valid. Любая повторная операция модификации переключает состояние страницы на Invalid, а измененная информация записывается в какую-либо другую Erased страницу, переводя ее в состояние Valid и, естественно, меняя ссылку на нее в таблице LBA->NAND.

Когда все страницы блока имеют статус Invalid, она снова очищается. Однако даже несколько страниц в состоянии Valid не позволят очистить блок, что приводит к внутренней фрагментации и не оптимальной утилизации ресурсов. Поэтому если в нескольких блоках страниц со статусом Erased уже не осталось, а количество Valid страниц стало меньше заданного уровня, содержимое этих блоков загружается в кэш, после чего все Valid данные консолидируются и вместе записываются в один из уже очищенных блоков. Ссылки на LBA перестраиваются, а освободившиеся блоки очищаются. Конечно, контроллер старается делать такую оптимизацию в периоды пониженной нагрузки.

Индивидуальная ячейка flash-памяти выдерживает ограниченное количество циклов перезаписи. Это связано с износом туннельного слоя, проводящего электроны. Ячейки SLC NAND в среднем выдерживают примерно 100 тыс. циклов стирания. Для увеличения сроков службы используются специальные технологии.
Одним из наиболее очевидных методов продления срока службы flash памяти является активное использование кэш самого накопителя. При работе с данными, в SDRAM создаются образы блоков. Внутренние контроллеры стараются объединять страницы в такие кэш-образы блоков и “сбрасывать” их на физические чипы NAND целиком в рамках единой операции. Конечно, если это не возможно, то операции записи на физический носитель могут осуществляться и постранично, но контроллер пытается избегать таких ситуаций.
Для более равномерного износа ячеек за счет оптимизации размещения и миграции данных между блоками используются технология wear-leveling. Общая сырая емкость накопителей flash- превышает адресное пространство, доступное для использования дисковыми массивами. Избыточная емкость (scratchpad), обычно составляет значительную часть общего объема. Так, scratchpad в дисках STEC 73GB составляет 43%, а в 400GB – 22%. Контроллеры накопителей имеют специальные счетчики количества циклов перезаписи ячеек и, в соответствии с этой информацией, равномерно используют все доступное дисковое пространство, при необходимости, перемещая данные в другие блоки. Необходимо заметить, что чем больше относительный объем scratchpad, тем проще найти свободное пространство для консолидации страниц.
Контроллер накопителя также следит за уровнем сигнала в используемых ячейках и, в случае каких-либо аномалий, оптимально перемещает такие блоки на новое место.
Естественно, внутренняя фрагментация накопителей flash очень сильно влияет на их производительность. Поэтому для получения релевантных результатов тестов, следует их проводить в, так называемом, стабильном состоянии (steady-state), когда все блоки, включая scratchpad, имеют записанные страницы. Максимальные результаты будут получены при операциях ввода-вывода равных размеру страницы.
Классический жесткий диск с интерфейсом Fibre Channel имеет 2 порта. Но т. к. единовременно возможно обращаться к данным, находящимся только в одной области магнитного диска, то и очередь обработки запросов всего одна. Flash накопители STEC имеют 16 независимых очередей и, соответственно, 16 Front-end каналов доступа. Выигрыш в производительности достигается за счет того, что контроллер накопителя имеет возможность параллельно выполнять в Back-end операции ввода-вывода из кэш на 16 независимых чипов NAND. В случае запросов на чтение, нагрузка на накопитель достаточно хорошо масштабируется до 25 параллельных запросов. Запись данных масштабируется до 8-10 запросов, что также является очень хорошим результатом.
При планировании размещения данных не стоит также забывать, что технологически операции чтения данных в SSD накопителях значительно быстрее записи.

Ячейки сгруппированы в страницы (pages) по 4KB (в накопителях первого поколения 73GB и 146GB) или 16KB (в накопителях 200GB и 400GB). Именно страница является атомарной единицей при обращении к SSD диску. Поэтому при записи порции данных размером меньше страницы, обязательна процедура read-modify-write при которой целая страница предварительно считывается с накопителя, в нее вносятся изменения и далее она снова записывается на SSD. Конечно, это сказывается на производительности записи.
Страницы, в свою очередь, сгруппированы в блоки (blocks) размером 256KB.

Для адресации страницы используется специальная таблица LBA->NAND. В ней каждому логическому адресу LBA ставится в соответствие физическая координата текущего местоположения данных, т. е. номера блока и страницы в нем. На рисунке ниже приведен пример адресации ячейки и записи данных. После выборки адреса блока и страницы, данные могут быть физически записаны в энергонезависимую память.

Биты готовой к записи ячейки всегда хранят значение 1 (низкий заряд). Переключение 1 в 0 является штатной операцией над индивидуальными ячейками. А вот переключение из 0 в 1 в flash NAND возможно только стиранием блока целиком. После этой операции все ячейки опять переводятся в состояние 1, а все страницы блока получают статус Erased. Первая запись данных в страницу изменяет ее статус на Valid. Любая повторная операция модификации переключает состояние страницы на Invalid, а измененная информация записывается в какую-либо другую Erased страницу, переводя ее в состояние Valid и, естественно, меняя ссылку на нее в таблице LBA->NAND.

Когда все страницы блока имеют статус Invalid, она снова очищается. Однако даже несколько страниц в состоянии Valid не позволят очистить блок, что приводит к внутренней фрагментации и не оптимальной утилизации ресурсов. Поэтому если в нескольких блоках страниц со статусом Erased уже не осталось, а количество Valid страниц стало меньше заданного уровня, содержимое этих блоков загружается в кэш, после чего все Valid данные консолидируются и вместе записываются в один из уже очищенных блоков. Ссылки на LBA перестраиваются, а освободившиеся блоки очищаются. Конечно, контроллер старается делать такую оптимизацию в периоды пониженной нагрузки.

Индивидуальная ячейка flash-памяти выдерживает ограниченное количество циклов перезаписи. Это связано с износом туннельного слоя, проводящего электроны. Ячейки SLC NAND в среднем выдерживают примерно 100 тыс. циклов стирания. Для увеличения сроков службы используются специальные технологии.
Одним из наиболее очевидных методов продления срока службы flash памяти является активное использование кэш самого накопителя. При работе с данными, в SDRAM создаются образы блоков. Внутренние контроллеры стараются объединять страницы в такие кэш-образы блоков и “сбрасывать” их на физические чипы NAND целиком в рамках единой операции. Конечно, если это не возможно, то операции записи на физический носитель могут осуществляться и постранично, но контроллер пытается избегать таких ситуаций.
Для более равномерного износа ячеек за счет оптимизации размещения и миграции данных между блоками используются технология wear-leveling. Общая сырая емкость накопителей flash- превышает адресное пространство, доступное для использования дисковыми массивами. Избыточная емкость (scratchpad), обычно составляет значительную часть общего объема. Так, scratchpad в дисках STEC 73GB составляет 43%, а в 400GB – 22%. Контроллеры накопителей имеют специальные счетчики количества циклов перезаписи ячеек и, в соответствии с этой информацией, равномерно используют все доступное дисковое пространство, при необходимости, перемещая данные в другие блоки. Необходимо заметить, что чем больше относительный объем scratchpad, тем проще найти свободное пространство для консолидации страниц.
Контроллер накопителя также следит за уровнем сигнала в используемых ячейках и, в случае каких-либо аномалий, оптимально перемещает такие блоки на новое место.
Естественно, внутренняя фрагментация накопителей flash очень сильно влияет на их производительность. Поэтому для получения релевантных результатов тестов, следует их проводить в, так называемом, стабильном состоянии (steady-state), когда все блоки, включая scratchpad, имеют записанные страницы. Максимальные результаты будут получены при операциях ввода-вывода равных размеру страницы.
Классический жесткий диск с интерфейсом Fibre Channel имеет 2 порта. Но т. к. единовременно возможно обращаться к данным, находящимся только в одной области магнитного диска, то и очередь обработки запросов всего одна. Flash накопители STEC имеют 16 независимых очередей и, соответственно, 16 Front-end каналов доступа. Выигрыш в производительности достигается за счет того, что контроллер накопителя имеет возможность параллельно выполнять в Back-end операции ввода-вывода из кэш на 16 независимых чипов NAND. В случае запросов на чтение, нагрузка на накопитель достаточно хорошо масштабируется до 25 параллельных запросов. Запись данных масштабируется до 8-10 запросов, что также является очень хорошим результатом.
При планировании размещения данных не стоит также забывать, что технологически операции чтения данных в SSD накопителях значительно быстрее записи.
Подписаться на:
Сообщения (Atom)