20 апреля 2017 г.
2 августа 2011 г.
Новые возможности Fibre Channel 16Gbps
В конце прошлого года я попытался выдать военную тайну о новых функциях 16Gbps коммутаторов Brocade. Прошло пол года и в мае эти коммутаторы были наконец-то официально отрелизены. Пришло время более подробно разобраться, что из обещанного было реализовано и о каких новых функциях не говорили совсем. Пару месяцев назад я написал об этом статью и вот наконец-то ее хоть и в раздербаненном виде, но опубликовали здесь и здесь.
Мне все-таки больше нравится первоначальный вариант. Поэтому я решил поделиться с вами сокровенными знаниями в изначальном виде.
Иногда мне кажется, что чем точнее наука, тем более суеверными являются ученые. Вот взять Computer science и ИТ, как область ее прикладного применения.
Здесь гадания уже давно превратились в отдельный бизнес, дающий хлеб различным аналитикам, экспертам и, конечно, нашему брату журналисту. Существует масса глобальных и микро-предсказаний, куда будут двигаться технологии, когда потребитель увидит той или иной новый продукт или даже сбудутся ли гадания других гадалок (сколько копий поломано вокруг Закона Мура). Более того, иногда прогнозы становятся законами, уже не предсказывающими, а самостоятельно влияющими на всю индустрию.
Инфраструктура сетей хранения является одним из важнейших компонентов любого центра обработки данных. Поэтому потребитель особенно пристально следит за глобальными предсказаниями в этой области. Итак: “скорость передачи данных в SAN будет удваиваться каждые 3-4 года”.
Время пришло и наши ожидания сбылись. Компания Brocade объявила о выходе своих новых продуктов 16Gbps Fibre Channel. В чем же преимущество предложенных новых технологий и насколько они в данный момент востребованы потребителем? В этой статье я хочу порассуждать именно на эти темы. Причем наибольший акцент хотелось бы сделать не на количественных характеристиках: “быстрее, выше, сильнее”, это разумеется само собой, но не всегда является главным аргументом для приобретения новых продуктов, а на качественно новых их возможностях.

Коммутаторы 16Gbps построены на новых чипах ASIC шестого поколения, которые в продолжение старой традиции были названы Condor 3.
Важной особенностью нового ASIC является использование не классического кодировании 8b/10b, применяемого во всех предыдущих реализациях протокола Fibre Channel, а более экономичного 64b/66b. Международный Комитет Технологических Стандартов T11 постановил, что теперь именно такой способ кодирования сигналов будет стандартом для всех новых протоколов передачи, включая 10G Ethernet и 16G Fibre Channel. Ведь это позволяет снизить накладные расходы на кодирование с 25% до 3%.
Означает ли смена схемы кодирования протокола, что существующие у Заказчиков устройства, работающие на 2,4 или 8Gbps, будет нельзя подключать к новым коммутаторам? Конечно можно, защита инвестиций потребителей является одним из важнейших приоритетов. Condor 3 полнофункционально работает с оконечными устройствами и коммутаторами предыдущих поколений. В этом случае будет использоваться старая схема кодирования 8b/10b .
ASIC Condor 3 может осуществлять коммутацию 420 млн. фреймов в секунду. HBA 16Gbps обеспечивают пропускную способность до 500 тыс. операций ввода вывода в сек. (IOPS) Только вдумайтесь в эти огромные числа! Задержки при коммутации внутри чипа ASIC составляют максимум 0,8мкс, а между различными ASIC – всего 2,4мкс. Напомню, что время ожидания считывания данных с жесткого диска минимум на три порядка больше.
Так что можно однозначно говорить, что инфраструктура сети передачи данных, построенная на современном оборудовании Brocade никогда не станет бутылочным горлышком, ограничивающим количество IOPS или увеличивающим время отклика транзакционных приложений.
Для обеспечения высокого уровня производительности передачи данных между значительно удаленными друг от друга площадками, входящими в катастрофоустойчивый комплекс хранения, чипы Condor 3 имеют более 8 тыс. входных буферов, поддерживающих работу групп из 16 или 24 портов (в 32 и 48-портовых платах соответственно). Для поддержки мультиплексирования трафика 16Gbps внутри каналов DWDM предусмотрен режим работы на скорости 10Gbps.
Специальный режим исправления ошибок FEC (Forward Error Correction) при передаче данных между портами коммутаторов, работающими на скорости 16 или 10Gbps, вносит минимальную задержку 0,4мкс.
Для обеспечения большей гибкости обеспечения качества уровней сервиса (Quality Of Services, QoS), количество Virtual Channels (VC) было увеличено до 40. Также появилась возможность обнаружения и восстановления потерянных буферных кредитов на уровне Virtual Channels. В ASIC Condor 2 такая функциональность работала только на уровне физических портов.
Чипы Condor 3 совместно с новой версией операционной среды FOS 7.0 предлагают несколько совершенно новых функциональных возможностей. Это компрессия данных при передаче между портами коммутаторов (между 16Gbps E-портами). Алгоритм McLZO, разработанный для достижения максимальной скорости упаковки и распаковки данных, позволяет добиться уровня компрессии 2:1. Данная функциональность особенно актуальна в SAN с узким каналом между удаленными площадками.

Для увеличения уровня безопасности при передаче данных на дальние расстояния совместно с компрессией можно использовать шифрование данных. Шифрование осуществляется аппаратным способом прямо “на лету”. Применяется крипто-стойкий алгоритм AES-GCM с 256bit ключами. Использование возможностей компрессии и шифрования данных вносит совсем незначительные задержку 6мкс. и потому совершенно не влияет на производительность передачи данных.
Как вы помните, в продуктах Brocade 8Gbps появилась новая возможность объединения до трех директоров DCX или DCX-4S в единую высокопроизводительную фабрику при помощи линков ICL (Inter-Chassis Links). Второе поколение ICL в коммутаторах 16Gbps развивает эту идею. И здесь изменения значительны. Во первых, появилась возможность выбора топологии подключения директоров друг к другу. В относительно простых конфигурациях лучшим решением является объединение до трех директоров в топологию “каждый с каждым” (mesh). В SAN, требующих большого количества портов для подключения оконечных устройств, возможна организация топологии “центр-периферия” (core-edge), объединяющая при помощи линков ICL до шести директоров.

Вместо коротких 2м. медных кабелей в новом решении будут использоваться оптические линки длиной до 50м. Модули QSFP (Quad SFP) работают с четырьмя линками 16Gbps, идущими к различным ASIC на платах CR (Core Routing blades). Для обеспечения производительности и отказоустойчивости между директорами возможно подключение по меньшей мере четырьмя ICL, что гарантирует минимальную скорость межкоммутаторных соединений 256Gbps. Транкинг позволяет объединить до 4 ICL в единый агрегированный канал, увеличивая не только общую производительность, но и отказоустойчивость соединения.
Применение в качестве соединений коммутаторов не классических каналов ISL (Inter-Switch Link), а линков ICL позволяет использовать порты директоров только для подключения оконечных устройств. В максимальной конфигурации, отказ от iSL позволяет подключить в SAN на треть (33%) больше портов серверов и дисковых массивов.
Для передачи на скорости 16Gbps, в новых коммутаторах, естественно, будут использоваться новые оптические модули SFP. И в них Brocade тоже реализовала несколько новых инновационных улучшений.
Скорость передачи возрастает за счет увеличения частоты очень коротких лазерных импульсов, Однако, в оптических каналах передачи существует модовая дисперсия, искажающая форму этих импульсов, растягивая их во времени. Идущие друг за другом импульсы начинают накладываться друг на друга и их уже не возможно однозначно детектировать. Именно по этой причине длина оптических кабелей ограничена. При удвоении скорости передачи с 4Gbps до 8Gbps в кабелях OM2, максимальная длина кабеля уменьшилась аж в 3 раза с 150м. до 50м.
В новых SFP 16Gbps используется специальная синхронизирующая схема CDR (Clock and Data Recovery). За счет нее при увеличении скорости передачи с 8Gbps до 16Gbps в кабелях OM3, ограничение максимальной длины кабеля уменьшилась всего лишь в 1,5 раза с 150м. до 100м. Brocade разработала технологию при которой размер и стоимость дополнительной схемы CDR стали достаточно малы и их реализация в SFP практически не влияет на цену модулей.
Переход на новые 16Gbps SFP позволяет на 25% уменьшить энергопотребление в расчете на переданный бит информации. Один порт 16Gbps потребляет всего 0,75Вт, в то время как для работы двух портов 8Gbps необходим 1Вт. Казалось бы различие совершенно незначительно, однако, в масштабах большого ЦОД такое снижение энергопотребления и соответствующее уменьшение тепловыделения позволит несколько снизить операционные затраты на поддержание работы комплекса. Соглашусь, этот параметр не является сколько-нибудь значимым в контексте принятия решения в пользу перехода на новую инфраструктуру 16Gbps, однако все-таки приятен в качестве дополнительного “бонуса”.
С увеличение скорости передачи данных даже небольшие дефекты кабелей или коннекторов становятся критичными. Новый диагностический режим работы портов (D_Ports) позволяет значительно ускорить процесс тестирования кабельной системы, а также поиска и устранения неисправностей в фабрике. Тесты работоспособности модулей SFP, измерения длины кабелей, а также замеры задержек передач и различных метрик производительности выполняются на индивидуальных портах и никак не влияют на работоспособность остальной фабрики. Новая версия FOS 7.0 позволяет запускать тесты как из командной строки, так и применяя графический интерфейс. Расширенные возможности аудита различных событий в логах RASlogs и Audit Logs позволят получать подробную информацию о происходящих в SAN событиях.
Теперь немного о новшествах в администрировании и управлении. И здесь наиболее ярко выделяется новость о появлении давно ожидаемой функциональности динамического выделения ресурсов в фабрике (Dynamic Fabric Provisioning, DFP). Она позволяет значительно ускорить и упростить процесс зонирования и LUN-маскирования новых серверов с 16Gbps HBA, а также избежать перенастройки SAN в случае замены оборудования.
Как это работает? Не обошлось, конечно, без виртуализации. Коммутаторы в фабрике генерируют список возможных виртуальных адресов FA-WWN (Fabric-Assigned Port World Wide Names). Один или несколько FA-WWN назначаются конкретным физически портам. Далее адреса FA-WWN можно использовать для зонирования в фабрике или настройки LUN-маскирования на дисковых массивах.
При подключении сервера к физическому порту коммутатора, его HBA в процессе соединения с фабрикой (FLOGI) получают и назначают себе в качестве WNN виртуальный FA-WWN. Так как все необходимые настройки были сделаны заранее, ресурсы хранения сразу становятся доступны серверу. При замене HBA, новая карта получит и будет работать со старым FA-WWN. Соответственно, никакой перенастройки SAN не понадобится.
Преимущества функциональности DFP в администрировании SAN особенно заметны при использовании в сетях с большим количеством блейд-серверов, коммутаторы которых работают в режиме AG (Acess Gateway).
Мы поговорили о различных замечательных технических новшествах. Однако, сами по себе они вряд ли кому-нибудь нужны. В чем же заключаются реальные преимущества использования продуктов 16Gbps в комплексах хранения?
Во первых, это, конечно, большая пропускная способность каналов передачи. Однако, здесь сразу следует оговориться. Производительность инфраструктуры SAN является важным фактором не для всех типов задач. Так, большинство OLTP баз данных или Web-приложений очень чувствительны к ограничениям количества операций ввода-вывода и задержкам передачи. В тоже время суммарные объемы генерируемых ими данных не велики и обычно не могут загрузить даже 4Gbps каналы. Очевидно, что переключение таких серверов на инфраструктуру 16Gbps с точки зрения производительности не даст ни каких преимуществ.
В тоже время существует ряд задач, которым уже тесно в рамках производительности каналов 8Gbps, используемых в настоящее время. Это, конечно, резервное копирование и восстановление данных, класс приложений, которые называют интеллектуальный анализ данных (data mining), а также задачи потоковой обработки данных, например, видео-потоков. Преимущества “широких” каналов 16Gbps очевидны также при миграции данных. Так для переноса 1TB информации теперь понадобится всего лишь 10 минут. Согласитесь, звучит впечатляюще!
Преимущества централизованного администрирования, управления и гибкой доставки приложений в последнее время сделали очень популярной идею использования инфраструктуры виртуальных рабочих мест (Virtual Desktop Infrastructure, VDI). Однако, одновременная загрузка огромного количества пользовательских сессий, например, в начале рабочего дня, создает колоссальную нагрузку на SAN. И здесь использование инфраструктуры 16Gbps может существенно снизить время ожидания и общую удовлетворенность пользователей.
Надо отметить, что количество задач, требовательных к полосе пропускания каналов передачи, неуклонно растет. Усиливающаяся популярность технологий виртуализации, увеличение многопоточности приложений, использование больших объемов памяти RAM, производительных шин PCIe 3.0 и накопителей flash позволяют обрабатывать и передавать огромные потоки данных, что в свою очередь, требует от сети хранения данных все большей и большей производительности.
Увеличение пропускной способности каналов позволяет объединять коммутаторы в сети с требуемым уровнем переподписки, но меньшим количеством ISL. Особенно это актуально для блейд-серверов в которых используются внутренние коммутаторы-лезвия. В центрах обработки данных с большим количеством коммутаторов и блейд-серверов переход части инфраструктуры на 16Gbps коммутаторы значительно упростит работу с кабельной системой в целом (то, что в английской терминологии называется cable management), а также процедуры поиска и устранения неисправностей в SAN. Меньшее количество требуемых портов снижает общую стоимость владения.
Новая продуктовая линейка Brocade включает в себя два директора DCX 8510-8 и 8510-4, коммутатор 6510 и адаптеры 1860, которые могут работать как 16Gbps HBA и как карты 10Gbps Ethernet CNA. Крупные производители оборудования уже поддержали инициативу постепенного перехода на новые 16Gbps технологии. Так, мировой лидер в производстве систем хранения компания EMC самой первой объявила о своей поддержке этих продуктов Brocade в рамках семейства Connectrix.
В начале статьи мы начали говорить о предсказаниях. На самом деле я лукавил, прогнозы в области ИТ в большинстве своем делаются не по расположению звезд и форме кофейной гущи, а на основе “дорожных карт” производителей оборудования и ПО, а также понимания реальных потребностей потребителей.
Воспользуюсь случаем и сделаю и свой собственный прогноз. В течении ближайшего года технологии FC 16Gbps органично займут свою нишу в эволюционном развитии сетей хранения данных. Однако старые технологии 4Gbps и 8Gbps свои позиции сдадут не сразу, а будут вытесняться постепенно с появлением новых задач и ростом нагрузки на каналы передачи данных.
Наступают интересные времена, активное продвижение конвергентных сетей начинает заметно теснить старый добрый Fibre Channel SAN. Актуальная на сегодня задача построения облачных инфраструктур в ближайшие несколько лет подтолкнет потребителей к построению гибридных сетей передачи и хранения данных, включающих в себя как классические FC, так и новые CEE технологии.
Мне все-таки больше нравится первоначальный вариант. Поэтому я решил поделиться с вами сокровенными знаниями в изначальном виде.
Иногда мне кажется, что чем точнее наука, тем более суеверными являются ученые. Вот взять Computer science и ИТ, как область ее прикладного применения.
Здесь гадания уже давно превратились в отдельный бизнес, дающий хлеб различным аналитикам, экспертам и, конечно, нашему брату журналисту. Существует масса глобальных и микро-предсказаний, куда будут двигаться технологии, когда потребитель увидит той или иной новый продукт или даже сбудутся ли гадания других гадалок (сколько копий поломано вокруг Закона Мура). Более того, иногда прогнозы становятся законами, уже не предсказывающими, а самостоятельно влияющими на всю индустрию.
Инфраструктура сетей хранения является одним из важнейших компонентов любого центра обработки данных. Поэтому потребитель особенно пристально следит за глобальными предсказаниями в этой области. Итак: “скорость передачи данных в SAN будет удваиваться каждые 3-4 года”.
Время пришло и наши ожидания сбылись. Компания Brocade объявила о выходе своих новых продуктов 16Gbps Fibre Channel. В чем же преимущество предложенных новых технологий и насколько они в данный момент востребованы потребителем? В этой статье я хочу порассуждать именно на эти темы. Причем наибольший акцент хотелось бы сделать не на количественных характеристиках: “быстрее, выше, сильнее”, это разумеется само собой, но не всегда является главным аргументом для приобретения новых продуктов, а на качественно новых их возможностях.

Коммутаторы 16Gbps построены на новых чипах ASIC шестого поколения, которые в продолжение старой традиции были названы Condor 3.
Характеристики
|
Поколение ASIC
| ||||||
1
|
2
|
3
|
4
|
5
|
6
|
7
| |
Название ASIC
|
Stitch
|
Loom
|
Bloom, Bloom-II
|
Condor / Goldeneye
|
Condor 2 / Goldeneye 2
|
Condor 3
|
?
|
Количество портов ASIC
|
2
|
4
|
8
|
32 / 24
|
40 / 24
|
48
| |
Год выхода
|
1997
|
1999
|
2001
|
2004
|
2008
|
2011
|
2014
|
Кол-во портов
|
2
|
4
|
8
|
32 / 24
|
40 / 24
| ||
Скорость передачи
|
1,063Gbps
|
1,063Gbps
|
2,126Gbps
|
4,252Gbps
|
8,5Gbps
|
14,025Gbps
|
28,05Gbps
|
Кодирование
|
8B/10B
|
8B/10B
|
8B/10B
|
8B/10B
|
8B/10B
|
64B/66B
|
64B/66B
|
Теоретическая максимальная пропускная способность
|
103 MB/s
|
103 MB/s
|
206 MB/s
|
412 MB/s
|
825 MB/s
|
1642 MB/s
|
3284 MB/s
|
Реальная максимальная пропускная способность
|
90 MB/s
|
95 MB/s
|
190 MB/s
|
380 MB/s
|
760 MB/s
|
1552 MB/s
|
3104 MB/s
|
Важной особенностью нового ASIC является использование не классического кодировании 8b/10b, применяемого во всех предыдущих реализациях протокола Fibre Channel, а более экономичного 64b/66b. Международный Комитет Технологических Стандартов T11 постановил, что теперь именно такой способ кодирования сигналов будет стандартом для всех новых протоколов передачи, включая 10G Ethernet и 16G Fibre Channel. Ведь это позволяет снизить накладные расходы на кодирование с 25% до 3%.
Означает ли смена схемы кодирования протокола, что существующие у Заказчиков устройства, работающие на 2,4 или 8Gbps, будет нельзя подключать к новым коммутаторам? Конечно можно, защита инвестиций потребителей является одним из важнейших приоритетов. Condor 3 полнофункционально работает с оконечными устройствами и коммутаторами предыдущих поколений. В этом случае будет использоваться старая схема кодирования 8b/10b .
ASIC Condor 3 может осуществлять коммутацию 420 млн. фреймов в секунду. HBA 16Gbps обеспечивают пропускную способность до 500 тыс. операций ввода вывода в сек. (IOPS) Только вдумайтесь в эти огромные числа! Задержки при коммутации внутри чипа ASIC составляют максимум 0,8мкс, а между различными ASIC – всего 2,4мкс. Напомню, что время ожидания считывания данных с жесткого диска минимум на три порядка больше.
Так что можно однозначно говорить, что инфраструктура сети передачи данных, построенная на современном оборудовании Brocade никогда не станет бутылочным горлышком, ограничивающим количество IOPS или увеличивающим время отклика транзакционных приложений.
Для обеспечения высокого уровня производительности передачи данных между значительно удаленными друг от друга площадками, входящими в катастрофоустойчивый комплекс хранения, чипы Condor 3 имеют более 8 тыс. входных буферов, поддерживающих работу групп из 16 или 24 портов (в 32 и 48-портовых платах соответственно). Для поддержки мультиплексирования трафика 16Gbps внутри каналов DWDM предусмотрен режим работы на скорости 10Gbps.
Специальный режим исправления ошибок FEC (Forward Error Correction) при передаче данных между портами коммутаторов, работающими на скорости 16 или 10Gbps, вносит минимальную задержку 0,4мкс.
Для обеспечения большей гибкости обеспечения качества уровней сервиса (Quality Of Services, QoS), количество Virtual Channels (VC) было увеличено до 40. Также появилась возможность обнаружения и восстановления потерянных буферных кредитов на уровне Virtual Channels. В ASIC Condor 2 такая функциональность работала только на уровне физических портов.
Чипы Condor 3 совместно с новой версией операционной среды FOS 7.0 предлагают несколько совершенно новых функциональных возможностей. Это компрессия данных при передаче между портами коммутаторов (между 16Gbps E-портами). Алгоритм McLZO, разработанный для достижения максимальной скорости упаковки и распаковки данных, позволяет добиться уровня компрессии 2:1. Данная функциональность особенно актуальна в SAN с узким каналом между удаленными площадками.
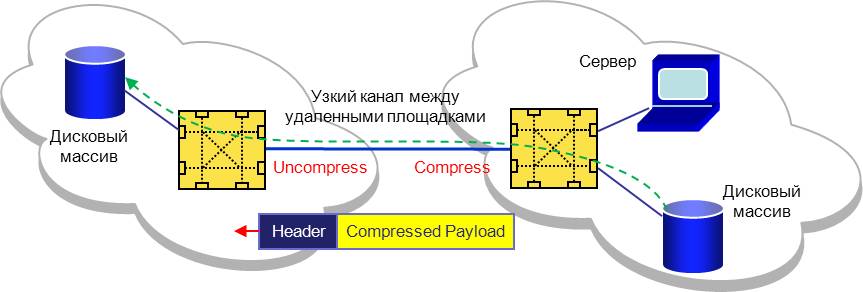
Для увеличения уровня безопасности при передаче данных на дальние расстояния совместно с компрессией можно использовать шифрование данных. Шифрование осуществляется аппаратным способом прямо “на лету”. Применяется крипто-стойкий алгоритм AES-GCM с 256bit ключами. Использование возможностей компрессии и шифрования данных вносит совсем незначительные задержку 6мкс. и потому совершенно не влияет на производительность передачи данных.
Как вы помните, в продуктах Brocade 8Gbps появилась новая возможность объединения до трех директоров DCX или DCX-4S в единую высокопроизводительную фабрику при помощи линков ICL (Inter-Chassis Links). Второе поколение ICL в коммутаторах 16Gbps развивает эту идею. И здесь изменения значительны. Во первых, появилась возможность выбора топологии подключения директоров друг к другу. В относительно простых конфигурациях лучшим решением является объединение до трех директоров в топологию “каждый с каждым” (mesh). В SAN, требующих большого количества портов для подключения оконечных устройств, возможна организация топологии “центр-периферия” (core-edge), объединяющая при помощи линков ICL до шести директоров.

Вместо коротких 2м. медных кабелей в новом решении будут использоваться оптические линки длиной до 50м. Модули QSFP (Quad SFP) работают с четырьмя линками 16Gbps, идущими к различным ASIC на платах CR (Core Routing blades). Для обеспечения производительности и отказоустойчивости между директорами возможно подключение по меньшей мере четырьмя ICL, что гарантирует минимальную скорость межкоммутаторных соединений 256Gbps. Транкинг позволяет объединить до 4 ICL в единый агрегированный канал, увеличивая не только общую производительность, но и отказоустойчивость соединения.
Применение в качестве соединений коммутаторов не классических каналов ISL (Inter-Switch Link), а линков ICL позволяет использовать порты директоров только для подключения оконечных устройств. В максимальной конфигурации, отказ от iSL позволяет подключить в SAN на треть (33%) больше портов серверов и дисковых массивов.
Для передачи на скорости 16Gbps, в новых коммутаторах, естественно, будут использоваться новые оптические модули SFP. И в них Brocade тоже реализовала несколько новых инновационных улучшений.
Скорость передачи возрастает за счет увеличения частоты очень коротких лазерных импульсов, Однако, в оптических каналах передачи существует модовая дисперсия, искажающая форму этих импульсов, растягивая их во времени. Идущие друг за другом импульсы начинают накладываться друг на друга и их уже не возможно однозначно детектировать. Именно по этой причине длина оптических кабелей ограничена. При удвоении скорости передачи с 4Gbps до 8Gbps в кабелях OM2, максимальная длина кабеля уменьшилась аж в 3 раза с 150м. до 50м.
|
Скорость передачи
|
Максимальная длина кабеля OM1
|
Максимальная длина кабеля OM2
|
Максимальная длина кабеля OM3
|
Максимальная длина кабеля OM4
|
|
1Gbps
|
300
|
500
|
860
|
-
|
|
2Gbps
|
150
|
300
|
500
|
-
|
|
4Gbps
|
50
|
150
|
380
|
400
|
|
8Gbps
|
21
|
50
|
150
|
190
|
|
16Gbps
|
15
|
35
|
100
|
125
|
В новых SFP 16Gbps используется специальная синхронизирующая схема CDR (Clock and Data Recovery). За счет нее при увеличении скорости передачи с 8Gbps до 16Gbps в кабелях OM3, ограничение максимальной длины кабеля уменьшилась всего лишь в 1,5 раза с 150м. до 100м. Brocade разработала технологию при которой размер и стоимость дополнительной схемы CDR стали достаточно малы и их реализация в SFP практически не влияет на цену модулей.
Переход на новые 16Gbps SFP позволяет на 25% уменьшить энергопотребление в расчете на переданный бит информации. Один порт 16Gbps потребляет всего 0,75Вт, в то время как для работы двух портов 8Gbps необходим 1Вт. Казалось бы различие совершенно незначительно, однако, в масштабах большого ЦОД такое снижение энергопотребления и соответствующее уменьшение тепловыделения позволит несколько снизить операционные затраты на поддержание работы комплекса. Соглашусь, этот параметр не является сколько-нибудь значимым в контексте принятия решения в пользу перехода на новую инфраструктуру 16Gbps, однако все-таки приятен в качестве дополнительного “бонуса”.
С увеличение скорости передачи данных даже небольшие дефекты кабелей или коннекторов становятся критичными. Новый диагностический режим работы портов (D_Ports) позволяет значительно ускорить процесс тестирования кабельной системы, а также поиска и устранения неисправностей в фабрике. Тесты работоспособности модулей SFP, измерения длины кабелей, а также замеры задержек передач и различных метрик производительности выполняются на индивидуальных портах и никак не влияют на работоспособность остальной фабрики. Новая версия FOS 7.0 позволяет запускать тесты как из командной строки, так и применяя графический интерфейс. Расширенные возможности аудита различных событий в логах RASlogs и Audit Logs позволят получать подробную информацию о происходящих в SAN событиях.
Теперь немного о новшествах в администрировании и управлении. И здесь наиболее ярко выделяется новость о появлении давно ожидаемой функциональности динамического выделения ресурсов в фабрике (Dynamic Fabric Provisioning, DFP). Она позволяет значительно ускорить и упростить процесс зонирования и LUN-маскирования новых серверов с 16Gbps HBA, а также избежать перенастройки SAN в случае замены оборудования.
Как это работает? Не обошлось, конечно, без виртуализации. Коммутаторы в фабрике генерируют список возможных виртуальных адресов FA-WWN (Fabric-Assigned Port World Wide Names). Один или несколько FA-WWN назначаются конкретным физически портам. Далее адреса FA-WWN можно использовать для зонирования в фабрике или настройки LUN-маскирования на дисковых массивах.
При подключении сервера к физическому порту коммутатора, его HBA в процессе соединения с фабрикой (FLOGI) получают и назначают себе в качестве WNN виртуальный FA-WWN. Так как все необходимые настройки были сделаны заранее, ресурсы хранения сразу становятся доступны серверу. При замене HBA, новая карта получит и будет работать со старым FA-WWN. Соответственно, никакой перенастройки SAN не понадобится.
Преимущества функциональности DFP в администрировании SAN особенно заметны при использовании в сетях с большим количеством блейд-серверов, коммутаторы которых работают в режиме AG (Acess Gateway).
Мы поговорили о различных замечательных технических новшествах. Однако, сами по себе они вряд ли кому-нибудь нужны. В чем же заключаются реальные преимущества использования продуктов 16Gbps в комплексах хранения?
Во первых, это, конечно, большая пропускная способность каналов передачи. Однако, здесь сразу следует оговориться. Производительность инфраструктуры SAN является важным фактором не для всех типов задач. Так, большинство OLTP баз данных или Web-приложений очень чувствительны к ограничениям количества операций ввода-вывода и задержкам передачи. В тоже время суммарные объемы генерируемых ими данных не велики и обычно не могут загрузить даже 4Gbps каналы. Очевидно, что переключение таких серверов на инфраструктуру 16Gbps с точки зрения производительности не даст ни каких преимуществ.
В тоже время существует ряд задач, которым уже тесно в рамках производительности каналов 8Gbps, используемых в настоящее время. Это, конечно, резервное копирование и восстановление данных, класс приложений, которые называют интеллектуальный анализ данных (data mining), а также задачи потоковой обработки данных, например, видео-потоков. Преимущества “широких” каналов 16Gbps очевидны также при миграции данных. Так для переноса 1TB информации теперь понадобится всего лишь 10 минут. Согласитесь, звучит впечатляюще!
Преимущества централизованного администрирования, управления и гибкой доставки приложений в последнее время сделали очень популярной идею использования инфраструктуры виртуальных рабочих мест (Virtual Desktop Infrastructure, VDI). Однако, одновременная загрузка огромного количества пользовательских сессий, например, в начале рабочего дня, создает колоссальную нагрузку на SAN. И здесь использование инфраструктуры 16Gbps может существенно снизить время ожидания и общую удовлетворенность пользователей.
Надо отметить, что количество задач, требовательных к полосе пропускания каналов передачи, неуклонно растет. Усиливающаяся популярность технологий виртуализации, увеличение многопоточности приложений, использование больших объемов памяти RAM, производительных шин PCIe 3.0 и накопителей flash позволяют обрабатывать и передавать огромные потоки данных, что в свою очередь, требует от сети хранения данных все большей и большей производительности.
Увеличение пропускной способности каналов позволяет объединять коммутаторы в сети с требуемым уровнем переподписки, но меньшим количеством ISL. Особенно это актуально для блейд-серверов в которых используются внутренние коммутаторы-лезвия. В центрах обработки данных с большим количеством коммутаторов и блейд-серверов переход части инфраструктуры на 16Gbps коммутаторы значительно упростит работу с кабельной системой в целом (то, что в английской терминологии называется cable management), а также процедуры поиска и устранения неисправностей в SAN. Меньшее количество требуемых портов снижает общую стоимость владения.
Новая продуктовая линейка Brocade включает в себя два директора DCX 8510-8 и 8510-4, коммутатор 6510 и адаптеры 1860, которые могут работать как 16Gbps HBA и как карты 10Gbps Ethernet CNA. Крупные производители оборудования уже поддержали инициативу постепенного перехода на новые 16Gbps технологии. Так, мировой лидер в производстве систем хранения компания EMC самой первой объявила о своей поддержке этих продуктов Brocade в рамках семейства Connectrix.
В начале статьи мы начали говорить о предсказаниях. На самом деле я лукавил, прогнозы в области ИТ в большинстве своем делаются не по расположению звезд и форме кофейной гущи, а на основе “дорожных карт” производителей оборудования и ПО, а также понимания реальных потребностей потребителей.
Воспользуюсь случаем и сделаю и свой собственный прогноз. В течении ближайшего года технологии FC 16Gbps органично займут свою нишу в эволюционном развитии сетей хранения данных. Однако старые технологии 4Gbps и 8Gbps свои позиции сдадут не сразу, а будут вытесняться постепенно с появлением новых задач и ростом нагрузки на каналы передачи данных.
Наступают интересные времена, активное продвижение конвергентных сетей начинает заметно теснить старый добрый Fibre Channel SAN. Актуальная на сегодня задача построения облачных инфраструктур в ближайшие несколько лет подтолкнет потребителей к построению гибридных сетей передачи и хранения данных, включающих в себя как классические FC, так и новые CEE технологии.
5 июня 2011 г.
Уильям Шокли
В истории науки много очень одиозных фигур. Уильям Шокли как раз такой. Он сумел прославится в двух своих ипостасях: с одной стороны как выдающийся ученый (помните из курса физики его транзистор?), а с другой стороны как популяризатор идей генетически определенного интеллектуального превосходства одних людей над другими. Причем, второй своей деятельностью он известен даже более, чем первой.
 Ну что же, теорию поверяем экспериментом. Окружающий меня ворох электроники подтверждает тот факт, что принципы, заложенные в транзистор работают. А вот общение с моим старым приятелем, здоровеееенным таким черным уроженцем Тринидада, а последние 25 лет нативным Американцем, умницей с совершенно русской душой, расизму не способствует. Ну и оставим все это на совести товарища Шокли и просто посмотрим на его интересную биографию.
Ну что же, теорию поверяем экспериментом. Окружающий меня ворох электроники подтверждает тот факт, что принципы, заложенные в транзистор работают. А вот общение с моим старым приятелем, здоровеееенным таким черным уроженцем Тринидада, а последние 25 лет нативным Американцем, умницей с совершенно русской душой, расизму не способствует. Ну и оставим все это на совести товарища Шокли и просто посмотрим на его интересную биографию.
Уильям Брэдфорд Шокли (Shockley) родился в Лондоне (1910 г.), но в раннем детстве с семьей переехал в Калифорнию. Физикой заинтересовался под влиянием соседа, преподававшего сию науку в Станфордском университете. Школа, бакалавриат, аспирантура в знаменитом ныне MIT. Докторская диссертация по физике твердого тела. Здесь я отвлекусь, стукну себя пяткой в грудь и пустив скупую слезу вспомню, что тоже ФТТ заканчивал... но не там... и без аспирантур... и единственное, что помню из Физики, так EMC, как минимум в квадрате (на правах рекламы) ;)) .
В 1936 г. Шокли начинает работать в лаборатории телефонной компании Bell, где предложил план разработки твердотельных усилителей как альтернативы вакуумным электронным лампам. Однако, в то время с соответствующими материалами было туго и его идея не осуществилась.
Во время второй мировой войны Уильям Шокли работает над военными проектами, в частности над электроникой полевой радарной станции. Позже он участвует в исследованиях противолодочных операций, решая такие задачи, как разработка оптимальных схем сбрасывания глубинных бомб при охоте за подводными лодками и выбор времени и целей для бомбардировочной авиации.
По окончании войны Шокли возвращается в Bell Labs в качестве директора программы исследований по физике твердого тела. К тому времени наиболее важными и распространенными электронными устройствами были усилительные лампы. Однако срок их службы был достаточно коротким, для подогрева катодов требовался дополнительный расход энергии, а сами хрупкие стекляшки занимали много места. Группа Шокли надеялись преодолеть эти недостатки, надеясь найти способ использования полупроводниковых элементов.
Уже через 2 года они достигли первого успеха, построив транзистор на основе германия. А идея замены точечных контактов выпрямляющими переходами между областями p- и n-типа в том же кристалле, привела к появлению плоскостного транзистора.

В 1956г. Шокли и два других члена его исследовательской группы Бардин и Браттейн за свою работу были удостоены Нобелевской премии. На церемонии презентации член Шведской королевской академии наук Рудберг назвал их достижение «образцом предвидения, остроумия и настойчивости в достижении цели».
После ухода из Bell Labs Шокли создает свою собственную компанию Shockley Semiconductor Laboratory. Он часто говорил, что главной целью является сделать миллион долларов, по тем временам огромнейшие деньги. У Шокли была идея, как удешевить транзисторы. Всего-то надо было научится делать их не из дорогого германия, а из очень дешевого кремния.
Расположить новую компанию решили в Калифорнии в маленьком городке Маунтин-Вью. Причин для этого было две: во-первых, недалеко оттуда жила мать Шокли, а во-вторых, Стэнфордский университет владел землей в Маунтин-Вью и предоставлял её инновационным компаниям на очень выгодных условиях. Предприятие, занимавшееся кремниевыми полупроводниками, стало первым в местечке, которое чуть позднее получило неофициальное название Кремниевая долина (многие предпочитают называть ее Силиконовой, так, конечно, не грамотно, но зато намного приятнее на ощупь :) ).
В общем Шокли чувствовал, что находится в нужном месте и в нужное время на переднем крае истории. Осталось только найти подходящих людей. И здесь педант вовсе не хотел полагаться на случайности. Он пытался, но так и не смог привлечь в свою компанию своих бывших сотрудников из Bell Labs. В итоге он сформировал группу из молодых специалистов по электронике, недавно окончивших американские университеты.

Однако отбор претендентов был очень жесткий. Цитата из книжки "Как сдвинуть гору Фудзи?":
"В тот день он интервьюировал Джима Гиббонса - молодого парня лет двадцати с небольшим. Гиббонc уже защитил докторскую диссертацию в Стэнфорде. Он также учился в Кембридже, так как выиграл Фулбрайтовскую стипендию. Все это происходило во временном офисе Шокли - ангаре из гофрированного железа. Гиббонс и Шокли уселись друг напротив друга, Шокли взял секундомер и задал первый вопрос.
В теннисном турнире сто двадцать семь участников, - размеренно произнес он. - В первом туре сто двадцать шесть игроков составят шестьдесят три пары, победители которых выйдут в следующий тур, и еще один игрок выходит во второй тур без игры. В
следующем туре - шестьдесят четыре игрока сыграют тридцать два матча. Сколько всего матчей понадобится, чтобы определить победителя?
Шокли включил секундомер. Прошло меньше минуты, и Гиббонс ответил: «Сто двадцать шесть». «Как вы догадались? - спросил Шокли. - Вы знали ответ заранее?»
Гиббонс просто объяснил, что каждый игрок перед тем, как его выбьют из турнира, должен сыграть хотя бы один матч. Для того чтобы определить победителя, 126 игроков должны проиграть, следовательно, понадобится именно 126 матчей.
Шокли чуть не сорвался от раздражения: именно таким способом он сам решил эту задачу, сказал он Гиббонсу. Гиббонс почувствовал, что Шокли не нравится, когда другие с такой легкостью могут использовать «его» метод.
Шокли сообщил условия следующей задачи и снова включил секундомер. Эта задача оказалась для Гиббонса более трудной. Он обдумывал ее уже довольно долго и не находил ответа. Гиббонc заметил, что с каждой минутой атмосфера становилось менее напряженной.
Шокли, у которого его быстрый ответ на первую задачу вызвал раздражение, теперь расслабился, как человек, комфортно расположившийся в теплой ванне. Наконец Шокли остановил секундомер и сказал, что на решение второй задачи Гиббонc уже потратил вдвое больше времени, чем сотрудники его лаборатории в среднем. Он заявил это с заметным удовлетворением. Гиббонc был принят на работу."
Надо отметить, что многим сотрудникам не нравился такой высокомерный и даже параноидальный стиль управления Шокли. Известен случай, когда его секретарь порезала палец, и он чтобы найти виновного заставил всех сотрудников компании пройти проверку на детекторе лжи. Позднее все-таки выяснилось, что секретарь сама нечаянно порезалась канцелярской кнопкой.
Решение Шокли прекратить перспективные исследования в области кремниевых полупроводников для сотрудников стало последней каплей. Восемь молодых сотрудников, которую назвали «вероломной восьмеркой» предложила главному инвестору компании Бекману заменить Шокли на профессионального менеджера. Бекман отказался. Тогда парни уволились и основали свою собственную компанию Fairchild Semiconductor (все еще существует). Кстати, среди отщепенцев были знаменитые ныне основатели Intel Гордон Мур и Роберт Нойс.
С уходом восьмерки, Shockley Semiconductor Laboratory потеряла большую часть своих лучших сотрудников; через несколько месяцев закрылась.
В 1963 г. Шокли стал преподавать в Станфордском университете. Там он серьезно заинтересовался идеями улучшения общества, которые в итоге вызвали горячие споры среди ученых-генетиков. Шокли утверждал, что человечеству угрожает своего рода «ухудшение породы», поскольку у людей с более низким коэффициентом умственного развития рождается больше детей, чем у людей с высоким IQ.
Многие его высказывания были очень резкими и одиозными. Так, он прочел целую серию лекций, в которых призывал к стерилизации малообеспеченных негритянок. Шокли неоднократно публично заявлял о том, что несколько порций его спермы хранится в специальном банке спермы, созданным для искусственного оплодотворения высокоинтеллектуальных женщин семенем лауреатов Нобелевской премии для появления на свет сверходаренных детей.
Шокли два раза. был женат. Второй раз, кстати, на медицинской сестре по уходу за псих-больными. В молодые годы он был заядлым альпинистом. По словам его второй жены, Уильям относился к альпинизму не как к отдыху, а как к еще одной серьезной проблеме, которую требовалось решить. В более зрелом возрасте он предпочитал заниматься парусным спортом, плаванием и нырянием за жемчугом.
Вот такой вот интересный и противоречивый человек. Ну что же, у каждого свои тараканы... Хм, надо и себе для проформы завести парочку... ;)

Уильям Брэдфорд Шокли (Shockley) родился в Лондоне (1910 г.), но в раннем детстве с семьей переехал в Калифорнию. Физикой заинтересовался под влиянием соседа, преподававшего сию науку в Станфордском университете. Школа, бакалавриат, аспирантура в знаменитом ныне MIT. Докторская диссертация по физике твердого тела. Здесь я отвлекусь, стукну себя пяткой в грудь и пустив скупую слезу вспомню, что тоже ФТТ заканчивал... но не там... и без аспирантур... и единственное, что помню из Физики, так EMC, как минимум в квадрате (на правах рекламы) ;)) .
В 1936 г. Шокли начинает работать в лаборатории телефонной компании Bell, где предложил план разработки твердотельных усилителей как альтернативы вакуумным электронным лампам. Однако, в то время с соответствующими материалами было туго и его идея не осуществилась.
Во время второй мировой войны Уильям Шокли работает над военными проектами, в частности над электроникой полевой радарной станции. Позже он участвует в исследованиях противолодочных операций, решая такие задачи, как разработка оптимальных схем сбрасывания глубинных бомб при охоте за подводными лодками и выбор времени и целей для бомбардировочной авиации.
По окончании войны Шокли возвращается в Bell Labs в качестве директора программы исследований по физике твердого тела. К тому времени наиболее важными и распространенными электронными устройствами были усилительные лампы. Однако срок их службы был достаточно коротким, для подогрева катодов требовался дополнительный расход энергии, а сами хрупкие стекляшки занимали много места. Группа Шокли надеялись преодолеть эти недостатки, надеясь найти способ использования полупроводниковых элементов.
Уже через 2 года они достигли первого успеха, построив транзистор на основе германия. А идея замены точечных контактов выпрямляющими переходами между областями p- и n-типа в том же кристалле, привела к появлению плоскостного транзистора.

В 1956г. Шокли и два других члена его исследовательской группы Бардин и Браттейн за свою работу были удостоены Нобелевской премии. На церемонии презентации член Шведской королевской академии наук Рудберг назвал их достижение «образцом предвидения, остроумия и настойчивости в достижении цели».
После ухода из Bell Labs Шокли создает свою собственную компанию Shockley Semiconductor Laboratory. Он часто говорил, что главной целью является сделать миллион долларов, по тем временам огромнейшие деньги. У Шокли была идея, как удешевить транзисторы. Всего-то надо было научится делать их не из дорогого германия, а из очень дешевого кремния.
Расположить новую компанию решили в Калифорнии в маленьком городке Маунтин-Вью. Причин для этого было две: во-первых, недалеко оттуда жила мать Шокли, а во-вторых, Стэнфордский университет владел землей в Маунтин-Вью и предоставлял её инновационным компаниям на очень выгодных условиях. Предприятие, занимавшееся кремниевыми полупроводниками, стало первым в местечке, которое чуть позднее получило неофициальное название Кремниевая долина (многие предпочитают называть ее Силиконовой, так, конечно, не грамотно, но зато намного приятнее на ощупь :) ).
В общем Шокли чувствовал, что находится в нужном месте и в нужное время на переднем крае истории. Осталось только найти подходящих людей. И здесь педант вовсе не хотел полагаться на случайности. Он пытался, но так и не смог привлечь в свою компанию своих бывших сотрудников из Bell Labs. В итоге он сформировал группу из молодых специалистов по электронике, недавно окончивших американские университеты.
Однако отбор претендентов был очень жесткий. Цитата из книжки "Как сдвинуть гору Фудзи?":
"В тот день он интервьюировал Джима Гиббонса - молодого парня лет двадцати с небольшим. Гиббонc уже защитил докторскую диссертацию в Стэнфорде. Он также учился в Кембридже, так как выиграл Фулбрайтовскую стипендию. Все это происходило во временном офисе Шокли - ангаре из гофрированного железа. Гиббонс и Шокли уселись друг напротив друга, Шокли взял секундомер и задал первый вопрос.
В теннисном турнире сто двадцать семь участников, - размеренно произнес он. - В первом туре сто двадцать шесть игроков составят шестьдесят три пары, победители которых выйдут в следующий тур, и еще один игрок выходит во второй тур без игры. В
следующем туре - шестьдесят четыре игрока сыграют тридцать два матча. Сколько всего матчей понадобится, чтобы определить победителя?
Шокли включил секундомер. Прошло меньше минуты, и Гиббонс ответил: «Сто двадцать шесть». «Как вы догадались? - спросил Шокли. - Вы знали ответ заранее?»
Гиббонс просто объяснил, что каждый игрок перед тем, как его выбьют из турнира, должен сыграть хотя бы один матч. Для того чтобы определить победителя, 126 игроков должны проиграть, следовательно, понадобится именно 126 матчей.
Шокли чуть не сорвался от раздражения: именно таким способом он сам решил эту задачу, сказал он Гиббонсу. Гиббонс почувствовал, что Шокли не нравится, когда другие с такой легкостью могут использовать «его» метод.
Шокли сообщил условия следующей задачи и снова включил секундомер. Эта задача оказалась для Гиббонса более трудной. Он обдумывал ее уже довольно долго и не находил ответа. Гиббонc заметил, что с каждой минутой атмосфера становилось менее напряженной.
Шокли, у которого его быстрый ответ на первую задачу вызвал раздражение, теперь расслабился, как человек, комфортно расположившийся в теплой ванне. Наконец Шокли остановил секундомер и сказал, что на решение второй задачи Гиббонc уже потратил вдвое больше времени, чем сотрудники его лаборатории в среднем. Он заявил это с заметным удовлетворением. Гиббонc был принят на работу."
Надо отметить, что многим сотрудникам не нравился такой высокомерный и даже параноидальный стиль управления Шокли. Известен случай, когда его секретарь порезала палец, и он чтобы найти виновного заставил всех сотрудников компании пройти проверку на детекторе лжи. Позднее все-таки выяснилось, что секретарь сама нечаянно порезалась канцелярской кнопкой.
Решение Шокли прекратить перспективные исследования в области кремниевых полупроводников для сотрудников стало последней каплей. Восемь молодых сотрудников, которую назвали «вероломной восьмеркой» предложила главному инвестору компании Бекману заменить Шокли на профессионального менеджера. Бекман отказался. Тогда парни уволились и основали свою собственную компанию Fairchild Semiconductor (все еще существует). Кстати, среди отщепенцев были знаменитые ныне основатели Intel Гордон Мур и Роберт Нойс.
С уходом восьмерки, Shockley Semiconductor Laboratory потеряла большую часть своих лучших сотрудников; через несколько месяцев закрылась.
В 1963 г. Шокли стал преподавать в Станфордском университете. Там он серьезно заинтересовался идеями улучшения общества, которые в итоге вызвали горячие споры среди ученых-генетиков. Шокли утверждал, что человечеству угрожает своего рода «ухудшение породы», поскольку у людей с более низким коэффициентом умственного развития рождается больше детей, чем у людей с высоким IQ.
Многие его высказывания были очень резкими и одиозными. Так, он прочел целую серию лекций, в которых призывал к стерилизации малообеспеченных негритянок. Шокли неоднократно публично заявлял о том, что несколько порций его спермы хранится в специальном банке спермы, созданным для искусственного оплодотворения высокоинтеллектуальных женщин семенем лауреатов Нобелевской премии для появления на свет сверходаренных детей.
Шокли два раза. был женат. Второй раз, кстати, на медицинской сестре по уходу за псих-больными. В молодые годы он был заядлым альпинистом. По словам его второй жены, Уильям относился к альпинизму не как к отдыху, а как к еще одной серьезной проблеме, которую требовалось решить. В более зрелом возрасте он предпочитал заниматься парусным спортом, плаванием и нырянием за жемчугом.
Вот такой вот интересный и противоречивый человек. Ну что же, у каждого свои тараканы... Хм, надо и себе для проформы завести парочку... ;)
31 мая 2011 г.
Контроль передачи данных в конвергентных сетях. часть 3
Часть 2 здесь
Давайте сравним методы контроля передачи данных в Fibre Channel и 10GE. Основная из задача – обеспечивать временную остановку передачи данных в случае нехватки входящих буферов портов-получателей. Напомню, что в FC используется механизм контроля счетчиков буферных кредитов. Объединяясь в фабрику, порты коммутаторов обмениваются информацией об общем количестве входных буферов и выставляют соответствующие значения счетчиков буферных кредитов (BB-credits). Отправив пакет, порт декрементирует свой счетчик. Если он обнуляется, отправитель должен остановить передачу. Порт-получатель в свою очередь, обязан явно сообщать о каждой освободившейся ячейке буфера посылкой слова-примитива Receiver Ready (R_RDY), Получив R_RDY, порт получатель инктеменитует значение BB credits.
Такой механизм гарантирует, что порты отправитель и получатель всегда имеют точную информацию о количестве свободных буферов на другом конце линка.

Очень важно отметить, что R_RDY является не FC фреймом (с заголовком, payload, CRC и т. д.), а 4byte (40bit) словом, т. е. объектом минимального размера, допустим для передачи по протоколу Fibre Channel. Соответственно, с точки зрения утилизации каналов накладные расходы контроля передачи данных практически не заметны.
Однако у каждой медали есть обратная сторона. Время между отправкой фрейма и получением сигнала R_RDY сильно зависит от расстояния между портами. Чем больше расстояние, тем дольше отправитель должен ждать инкрементации BB Credits. А это, в случае нехватки кредитов, приводит к задержкам передачи данных и падению загрузки линка.

На приведенном графике значение длины линка, при котором начинается падение утилизации канала, зависит от скорости передачи (Transfer Rate) и количества входных буферов. Увеличение количества доступных входных буферов, приводит к тому, счетчик буферных кредитов обнулится на больших расстояниях. Соответственно, точка перегиба на графике сдвигается вправо.

Давайте теперь рассмотрим протокол Ethernet. Он не имеет примитивов и предусматривает передачу данных в сети только фреймами. Минимальный размер фрейма 64bytes. Если бы в этом протоколе контроль передачи данных был реализован таким же образом, как и в FC, он был бы в 16 раз менее эффективным. Поэтому и был выбран другой метод. Вместо того чтобы постоянно сообщать о количестве свободных буферов, устройства в Ethernet явно сообщают только о событии, когда их не хватает. Таким образом, существенно экономится пропускная способность каналов.

Главным недостатком этого механизма является то, что как и в Fibre Channel, общая эффективность контроля передачи данных заметно падает с увеличением длины линка. Утилизация длинных линков становится низкой.

Для полной загрузки линков на больших расстояниях необходимо либо отключать механизм контроля передачи, либо увеличивать количество входных буферов в коммутаторах, соответствующим образом сдвинув пороговые значения.

На самом деле это выбор без выбора, ведь с отключением Flow Control появится вероятность потери фреймов, что для трафика FCoE совершенно не приемлемо. Поэтому производители увеличивают количество буферных ячеек. На данный момент Cisco повысила максимальную длину линков между своими коммутаторами с 300м. до 3км. (NX-OS 5.0(2)N1.1).
Brocade, вроде, пока ограничивает длину линков 300м.
Давайте сравним методы контроля передачи данных в Fibre Channel и 10GE. Основная из задача – обеспечивать временную остановку передачи данных в случае нехватки входящих буферов портов-получателей. Напомню, что в FC используется механизм контроля счетчиков буферных кредитов. Объединяясь в фабрику, порты коммутаторов обмениваются информацией об общем количестве входных буферов и выставляют соответствующие значения счетчиков буферных кредитов (BB-credits). Отправив пакет, порт декрементирует свой счетчик. Если он обнуляется, отправитель должен остановить передачу. Порт-получатель в свою очередь, обязан явно сообщать о каждой освободившейся ячейке буфера посылкой слова-примитива Receiver Ready (R_RDY), Получив R_RDY, порт получатель инктеменитует значение BB credits.
Такой механизм гарантирует, что порты отправитель и получатель всегда имеют точную информацию о количестве свободных буферов на другом конце линка.
Очень важно отметить, что R_RDY является не FC фреймом (с заголовком, payload, CRC и т. д.), а 4byte (40bit) словом, т. е. объектом минимального размера, допустим для передачи по протоколу Fibre Channel. Соответственно, с точки зрения утилизации каналов накладные расходы контроля передачи данных практически не заметны.
Однако у каждой медали есть обратная сторона. Время между отправкой фрейма и получением сигнала R_RDY сильно зависит от расстояния между портами. Чем больше расстояние, тем дольше отправитель должен ждать инкрементации BB Credits. А это, в случае нехватки кредитов, приводит к задержкам передачи данных и падению загрузки линка.
На приведенном графике значение длины линка, при котором начинается падение утилизации канала, зависит от скорости передачи (Transfer Rate) и количества входных буферов. Увеличение количества доступных входных буферов, приводит к тому, счетчик буферных кредитов обнулится на больших расстояниях. Соответственно, точка перегиба на графике сдвигается вправо.
Давайте теперь рассмотрим протокол Ethernet. Он не имеет примитивов и предусматривает передачу данных в сети только фреймами. Минимальный размер фрейма 64bytes. Если бы в этом протоколе контроль передачи данных был реализован таким же образом, как и в FC, он был бы в 16 раз менее эффективным. Поэтому и был выбран другой метод. Вместо того чтобы постоянно сообщать о количестве свободных буферов, устройства в Ethernet явно сообщают только о событии, когда их не хватает. Таким образом, существенно экономится пропускная способность каналов.
Главным недостатком этого механизма является то, что как и в Fibre Channel, общая эффективность контроля передачи данных заметно падает с увеличением длины линка. Утилизация длинных линков становится низкой.
Для полной загрузки линков на больших расстояниях необходимо либо отключать механизм контроля передачи, либо увеличивать количество входных буферов в коммутаторах, соответствующим образом сдвинув пороговые значения.
На самом деле это выбор без выбора, ведь с отключением Flow Control появится вероятность потери фреймов, что для трафика FCoE совершенно не приемлемо. Поэтому производители увеличивают количество буферных ячеек. На данный момент Cisco повысила максимальную длину линков между своими коммутаторами с 300м. до 3км. (NX-OS 5.0(2)N1.1).
- Nexus 55xx - Nexus 55xx – 3км.
- Nexus 50x0 - Nexus 50x0 - 3 км.
- Nexus 50x0 - Nexus 55xx - 3 км.
- Nexus 55xx - Nexus 2232 – 300м.
- Nexus 50x0 - Nexus 2232 – 300м.
Brocade, вроде, пока ограничивает длину линков 300м.
18 мая 2011 г.
Контроль передачи данных в конвергентных сетях. часть 2
Часть 1 здесь
Использовалась статья Cisco
Итак, мы остановились на том, что чем длиннее кабель, тем раньше должна быть передана пауза. Насколько раньше? Для того чтобы не потерять ни одного фрейма данных, “запаса” свободных буферов должно быть достаточно для сохранения всех фреймов которые будут посланы, пока PAUSE дойдет до отправителя и будет им обработана. Пороговое значение количества свободных буферов, при котором высылается пауза должно быть установлено, учитывая следующие факторы:




Суммарно, мы получаем постоянную задержку, эквивалентную 9216bytes (максимальное MTU Ethernet) + 3840bytes + 2240bytes (максимальное MTU FCoE) = 15296bytes, а также задержку, 1300bytes на каждые 100м. кабеля. На максимально допустимой в данный момент длине кабеля 300м. мы получим задержку эквивалентную 15296bytes + 3 * 1300bytes = 19196bytes.
Есть еще один момент, о котором не стоит забывать. Он заключается в том, что буферная память организована не как единое непрерывное хранилище данных, а виде отдельных ячеек или блоков. Размеры этих ячеек зависят от конкретной модели устройств. Так, Cisco в своих коммутаторах Nexus 5000 и экстендерах Nexus 2000 они составляют 160bytes и 80bytes соответственно.
Ethernet фрейм минимального размера 64bytes в буферах Nexus 5000 будет занимать всего 40% объема ячейки. А так как неиспользованная память в ячейках применяться для хранения других данных уже не может, оставшиеся 96bytes просто пропадают.

Итак, в самом худшем случае фреймов 64bytes мы имеем 60% накладные расходы на использованный объем буферной памяти. Наши 19196bytes поместятся в 300 пакетов размером 64bytes. Это, в свою очередь, приведет к использованию 300 * 160bytes = 48000bytes буферной памяти (около 1/10 от общего объема памяти в Nexus 5000).
Итак, в рассмотренном конкретном примере, пороговое значение, при котором высылается PAUSE на передачу FCoE, равно 300 буферных ячеек. Использование функциональности lossless Ethernet с другими сетевыми протоколами, например iSCSI, за счет снижения количества ретрансмитов данных дает дополнительные преимущества производительности. Однако, стоит учитывать, что в этом случае пороговое значение паузы будет еще выше. В случае Cisco Nexus 5000 оно будет равно 409 буферных ячеек.
В данный момент Cisco NX-OS поддерживает PFC только до 3 CoS:
Использовалась статья Cisco
Итак, мы остановились на том, что чем длиннее кабель, тем раньше должна быть передана пауза. Насколько раньше? Для того чтобы не потерять ни одного фрейма данных, “запаса” свободных буферов должно быть достаточно для сохранения всех фреймов которые будут посланы, пока PAUSE дойдет до отправителя и будет им обработана. Пороговое значение количества свободных буферов, при котором высылается пауза должно быть установлено, учитывая следующие факторы:
- Обмен данными возможен в обоих направлениях. Если порт получатель уже начал передавать какой-то пакет, то прерывать эту передачу для того, чтобы послать PAUSE не разумно. Поэтому будет задержка, достаточная для передачи данных объемом MTU-1bit (рассматриваем самый худший случай). Напоминаю, MTU = Maximum Transmission Unit. Так как MTU для различных CoS может быть разным, нужно брать максимальный.
- Скорость распространения электромагнитного сигнала в меди составляет около 70% от скорости в вакууме. В оптическом кабеле она еще чуть меньше и составляет 65%. Поэтому каждые 100м. кабеля добавляют 476нс. (медь) или 513нс. (оптика) задержки. За время пока PAUSE путешествует по 100м. кабелю, порт-отправитель на 10Gbps передаст 641byte (берем худший случай более медленной оптики). А так как на момент отправки PAUSE по кабелю к получателю уже передавались какие-то данные, этот объем надо удвоить. Округленно получаем 1300bytes на каждые 100м.
- При получении PAUSE порт получатель должен ее обработать и подать команду на остановку трафика. Протокол PFC предписывает это сделать не более чем за 60 квантов времени (кванты обсуждались в предыдущем посте), что эквивалентно передаче 512bits * 60 квантов = 3840bytes.
- После того, как послана команда на остановку трафика, необходимо все-таки дождаться, пока пакет, который уже начался передаваться, полностью уйдет. Соответственно, опять будет задержка, достаточная для передачи данных объемом MTU-1bit (самый плохой случай). причем здесь должно приниматься во внимание MTU только CoS FCoE.
Суммарно, мы получаем постоянную задержку, эквивалентную 9216bytes (максимальное MTU Ethernet) + 3840bytes + 2240bytes (максимальное MTU FCoE) = 15296bytes, а также задержку, 1300bytes на каждые 100м. кабеля. На максимально допустимой в данный момент длине кабеля 300м. мы получим задержку эквивалентную 15296bytes + 3 * 1300bytes = 19196bytes.
Есть еще один момент, о котором не стоит забывать. Он заключается в том, что буферная память организована не как единое непрерывное хранилище данных, а виде отдельных ячеек или блоков. Размеры этих ячеек зависят от конкретной модели устройств. Так, Cisco в своих коммутаторах Nexus 5000 и экстендерах Nexus 2000 они составляют 160bytes и 80bytes соответственно.
Ethernet фрейм минимального размера 64bytes в буферах Nexus 5000 будет занимать всего 40% объема ячейки. А так как неиспользованная память в ячейках применяться для хранения других данных уже не может, оставшиеся 96bytes просто пропадают.
Итак, в самом худшем случае фреймов 64bytes мы имеем 60% накладные расходы на использованный объем буферной памяти. Наши 19196bytes поместятся в 300 пакетов размером 64bytes. Это, в свою очередь, приведет к использованию 300 * 160bytes = 48000bytes буферной памяти (около 1/10 от общего объема памяти в Nexus 5000).
Итак, в рассмотренном конкретном примере, пороговое значение, при котором высылается PAUSE на передачу FCoE, равно 300 буферных ячеек. Использование функциональности lossless Ethernet с другими сетевыми протоколами, например iSCSI, за счет снижения количества ретрансмитов данных дает дополнительные преимущества производительности. Однако, стоит учитывать, что в этом случае пороговое значение паузы будет еще выше. В случае Cisco Nexus 5000 оно будет равно 409 буферных ячеек.
В данный момент Cisco NX-OS поддерживает PFC только до 3 CoS:
- 1x FCoE (mini Jumbo MTU 2240bytes)
- 1x сетевой трафик с jumbo MTU 9216bytes
- 1x сетевой трафик со стандартным MTU 1500bytes
16 мая 2011 г.
Контроль передачи данных в конвергентных сетях. часть 1
Использовалась статья Cisco
Традиционный протокол Ethernet изначально разрабатывался для передачи данных по ненадежным носителям. Он совсем не гарантирует того, что все посланные пакеты данных будут обязательно получены соответствующими устройствами.
Одной из причин ненадежности Ethernet заключается в отсутствии обратной связи между получателем данных и их отправителем. Проблема особенно критична в сетях с большим количеством хопов (hops). Часто бывает так, что отправитель передает данные с большей скоростью, чем получатель их обрабатывает. Это приводит к тому, что входные буферы получателя быстро заполняются (buffer overflow), а новые пакеты, которые хранить уже негде, просто отбрасываются (drop). Причем, никакого уведомления об этом отправитель не получает.
В сетях передачи данных такая ситуация не является критичной. Обнаружив, что каких-то Ethernet фреймов не хватает (drop detection), протоколы сетевого (3) уровня просят переслать их заново. Получив недостающие пакеты, эти протоколы их упорядочивают (in-order) и передают выше по стеку.
Ситуация значительно хуже в сетях хранения данных. Протокол Fibre Channel не осуществляет ретрансмиссию только отдельных фреймов (так же, как и не допускают доставку пакетов в неправильной последовательности - out of order delivery). В случае обнаружения потери части фреймов, устройствам приходится передавать заново всю последовательность (sequence). Естественно, это приводит к катастрофическому падению производительности.
Для того, чтобы избежать возможность потери фреймов в связи с переполнением входных буферов принимающих устройств, реализован специальный механизм контроля передачи данных (flow control). В “чистом” Fibre Channel этот механизм работает на уровне FC2. Он построен на первоначальном обмене информацией о количестве имеющихся в наличии входных буферов, дальнейшем уменьшении значений счетчиков буферных кредитов (BB credits) при отправке данных и их инкрементации при получении от порта-соседа коротких сообщений R_RDY об освобождении буферов. Подробнее в 3 части.
В конвергентных сетях на базе 10Gbps Ethernet при передаче FCoE трафика мы также обязаны использовать контроль передачи данных. Однако там для этого используется совсем другой подход. Порт-получатель данных постоянно следит за количеством своих свободных буферов. Как только он видит, что их количество достигает некого минимального уровня, порту-отправителю посылается специальный (MAC control frame) фрейм PAUSE, уведомляющий о необходимости на какое-то время приостановить передачу всех данных. Однако, такой подход не является оптимальным, так как в конвергентных сетях остановка FCoE трафика не должна приводить к задержке передачи данных других сетевых протоколов.
Поэтому механизм контроля передачи данных на базе PAUSE расширен функциональностью PFC (Priority Flow Control). Различным протоколам назначаются соответствующие классы сервиса (Classes of Services, CoS). Значение CoS передается в одном из полей VLAN-тега пакетов (VLAN tag). Контроль передачи осуществляется независимо для каждого из 8x возможных CoS. Структура пакетов не использующих и использующих PFC показана на рисунке.

Продолжительность паузы для каждого CoS определена в соответствующем 2byte поле количеством квантов времени. Один квант представляет собой время, необходимое для передачи 512bits данных на текущем Transfer Rate (в данном случае 10Gbps). Значение ноль принудительно снимает передачу данных с паузы.
Насколько я понял, в данный момент коммутаторы Cisco не пытаются интеллектуально подходить к определению необходимой продолжительности паузы. Вместо этого выставляется очень большое значение PAUSE, а затем явным образом снимается контрольным фреймом со значением 0. Как это работает у других, я не знаю.
Для того, чтобы установить паузу на передачу данных, порт получатель должен сгенерить управляющий фрейм, передать его по кабелям в виде оптического или электрического сигнала (ох, как я всем надоел своими сетованиями на то, что скорость распространения электромагнитной волны в нашей Вселенной такая маленькая ;) ), после чего этот фрейм должен быть обработан отправителем. Все это происходит отнюдь не мгновенно. Поэтому получатель должен постоянно следить за своими буферами и заранее (!) отправлять PAUSE, предполагая скорое переполнение своих буферов. Чем длиннее кабель, тем раньше должна быть передана пауза.
Часть 2 здесь...
Традиционный протокол Ethernet изначально разрабатывался для передачи данных по ненадежным носителям. Он совсем не гарантирует того, что все посланные пакеты данных будут обязательно получены соответствующими устройствами.
Одной из причин ненадежности Ethernet заключается в отсутствии обратной связи между получателем данных и их отправителем. Проблема особенно критична в сетях с большим количеством хопов (hops). Часто бывает так, что отправитель передает данные с большей скоростью, чем получатель их обрабатывает. Это приводит к тому, что входные буферы получателя быстро заполняются (buffer overflow), а новые пакеты, которые хранить уже негде, просто отбрасываются (drop). Причем, никакого уведомления об этом отправитель не получает.
В сетях передачи данных такая ситуация не является критичной. Обнаружив, что каких-то Ethernet фреймов не хватает (drop detection), протоколы сетевого (3) уровня просят переслать их заново. Получив недостающие пакеты, эти протоколы их упорядочивают (in-order) и передают выше по стеку.
Ситуация значительно хуже в сетях хранения данных. Протокол Fibre Channel не осуществляет ретрансмиссию только отдельных фреймов (так же, как и не допускают доставку пакетов в неправильной последовательности - out of order delivery). В случае обнаружения потери части фреймов, устройствам приходится передавать заново всю последовательность (sequence). Естественно, это приводит к катастрофическому падению производительности.
Для того, чтобы избежать возможность потери фреймов в связи с переполнением входных буферов принимающих устройств, реализован специальный механизм контроля передачи данных (flow control). В “чистом” Fibre Channel этот механизм работает на уровне FC2. Он построен на первоначальном обмене информацией о количестве имеющихся в наличии входных буферов, дальнейшем уменьшении значений счетчиков буферных кредитов (BB credits) при отправке данных и их инкрементации при получении от порта-соседа коротких сообщений R_RDY об освобождении буферов. Подробнее в 3 части.
В конвергентных сетях на базе 10Gbps Ethernet при передаче FCoE трафика мы также обязаны использовать контроль передачи данных. Однако там для этого используется совсем другой подход. Порт-получатель данных постоянно следит за количеством своих свободных буферов. Как только он видит, что их количество достигает некого минимального уровня, порту-отправителю посылается специальный (MAC control frame) фрейм PAUSE, уведомляющий о необходимости на какое-то время приостановить передачу всех данных. Однако, такой подход не является оптимальным, так как в конвергентных сетях остановка FCoE трафика не должна приводить к задержке передачи данных других сетевых протоколов.
Поэтому механизм контроля передачи данных на базе PAUSE расширен функциональностью PFC (Priority Flow Control). Различным протоколам назначаются соответствующие классы сервиса (Classes of Services, CoS). Значение CoS передается в одном из полей VLAN-тега пакетов (VLAN tag). Контроль передачи осуществляется независимо для каждого из 8x возможных CoS. Структура пакетов не использующих и использующих PFC показана на рисунке.
Продолжительность паузы для каждого CoS определена в соответствующем 2byte поле количеством квантов времени. Один квант представляет собой время, необходимое для передачи 512bits данных на текущем Transfer Rate (в данном случае 10Gbps). Значение ноль принудительно снимает передачу данных с паузы.
Насколько я понял, в данный момент коммутаторы Cisco не пытаются интеллектуально подходить к определению необходимой продолжительности паузы. Вместо этого выставляется очень большое значение PAUSE, а затем явным образом снимается контрольным фреймом со значением 0. Как это работает у других, я не знаю.
Для того, чтобы установить паузу на передачу данных, порт получатель должен сгенерить управляющий фрейм, передать его по кабелям в виде оптического или электрического сигнала (ох, как я всем надоел своими сетованиями на то, что скорость распространения электромагнитной волны в нашей Вселенной такая маленькая ;) ), после чего этот фрейм должен быть обработан отправителем. Все это происходит отнюдь не мгновенно. Поэтому получатель должен постоянно следить за своими буферами и заранее (!) отправлять PAUSE, предполагая скорое переполнение своих буферов. Чем длиннее кабель, тем раньше должна быть передана пауза.
Часть 2 здесь...
Подписаться на:
Сообщения (Atom)